

DeepSeekеЉЇеКњжЙУз†ідЄ≠е§ЦAIе§Іж®°еЮЛзЂЮжКАеЬЇеОЯжЬЙзЪДиІДеИЩпЉМ襀зІ∞дЄЇвАЬз•ЮзІШзЪДдЄЬжЦєеКЫйЗПвАЭпЉМеЃГзЪДеЗЇзО∞пЉМдїњдљЫйАРжЄРдЄЇAIзЪДиРљеЬ∞еЇФзФ®еЛЊеЛТеЗЇдЇЖдЄАдЄ™з°ЃеЃЪжАІзЪДжЬ™жЭ•иУЭеЫЊпЉМжВДзДґжЛЙеЉАдЇІдЄЪжХ∞жЩЇеМЦзЪДе§ІеєХгАВдїОдЄ≠пЉМжИСдїђеПѓдї•з™•иІБжЬ™жЭ•AIе§Іж®°еЮЛдЇІдЄЪеПСе±ХзЪДеЫЫе§ІиґЛеКњгАВ
дЄАпЉМж®°еЮЛињИињЫйЂШжАІдїЈжѓФжЧґеИїгАВ
ињЩеЗ†еєіпЉМAIе§Іж®°еЮЛзЪДеЕ•еЬЇйЧ®жІЫе±ЕйЂШдЄНдЄЛгАВдЄКдЄЗдЇњзЪДеПВжХ∞иІДж®°гАБиґЕеЉЇзЪДзЃЧеКЫжФѓжТСдї•еПКжµЈйЗПгАБдЉШиі®зЪДжХ∞жНЃиµДжЇРпЉМйГљжДПеС≥зЭАйЂШжШВзЪДеЕ•еЬЇдїЈж†ЉгАВ
дї•GPT-4дЄЇдЊЛпЉМеЕґиЃ≠зїГжХ∞жНЃйЗПйЂШиЊЊ13дЄЗдЇњtokenпЉМжґµзЫЦдЇЖдЇТиБФзљСеЕ®йҐЖеЯЯзЪДжЦЗжЬђгАВе¶Вж≠§жµЈйЗПзЪДжХ∞жНЃж†Зж≥®еЈ•дљЬдЄНдїЕжИРжЬђйЂШжШВпЉМиАМдЄФиАЧжЧґиієеКЫпЉМеѓєзЃЧеКЫзЪДйЬАж±ВдєЯжЮБдЄЇеЇЮе§ІпЉМдЊЭиµЦжХ∞дЄЗеЉ†A100 GPUйЫЖзЊ§пЉМеНХжђ°иЃ≠зїГжИРжЬђеН≥иґЕињЗ1дЇњзЊОеЕГгАВйЂШжШВзЪДжИРжЬђеТМиµДжЇРйЬАж±ВдљњеЕґжКАжЬѓеЊИйЪЊиРљеЬ∞пЉМжЫіеПѓжАХзЪДжШѓзГІйТ±жЬ™ењЕиГљжНҐжЭ•еЙНжЩѓгАВ
DeepSeekзЪДжЬАдЇЃзЬЉдєЛе§ДдєЯжБ∞еЬ®ж≠§пЉМеН≥еЕґеПѓдї•йАЪињЗзЇѓеЉЇеМЦе≠¶дє†пЉИRLпЉЙеЃЮзО∞вАЬиЗ™жИСињЫеМЦвАЭпЉМдљњеЕґеЬ®жХ∞жНЃеЗЖе§ЗжЦєйЭҐеЕЈжЬЙжШЊиСЧдЉШеКњгАВжЧ†йЬАж†Зж≥®жХ∞жНЃпЉМе∞±е§Іе§ІйЩНдљОдЇЖжХ∞жНЃеЗЖе§ЗзЪДжИРжЬђеТМйЪЊеЇ¶пЉМдЄЇеЉАеПСиАЕиКВзЬБдЇЖе§ІйЗПжЧґйЧіз≤ЊеКЫпЉМиЃ©дїЦдїђиГље§ЯжЫіеК†дЄУж≥®дЇОж®°еЮЛзЪДиЃ≠зїГеТМдЉШеМЦгАВ
еРМжЧґDeepSeekзЪДе•ЦеК±иЃЊиЃ°жЮБзЃАпЉМдїЕзФ®вАЬз≠Фж°Иж≠£з°ЃжАІвАЭеТМвАЬж†ЉеЉПиІДиМГвАЭдљЬдЄЇе•ЦеК±дњ°еПЈгАВзЃАжіБзЪДе•ЦеК±жЬЇеИґйБњеЕНдЇЖе§НжЭВе•ЦеК±ж®°еЮЛеПѓиГљеѓЉиЗізЪДдљЬеЉКй£ОйЩ©пЉМдљњж®°еЮЛиЃ≠зїГжЫідЄЇйЂШжХИгАБз®≥еЃЪпЉМињШиГље§ЯжЫіе•љеЬ∞еЉХеѓЉж®°еЮЛжЬЭж≠£з°ЃзЪДжЦєеРСеПСе±ХпЉМжПРйЂШж®°еЮЛзЪДиЃ≠зїГжХИжЮЬпЉМйБњеЕНдЄАдЇЫжДПжГ≥дЄНеИ∞зЪДжГЕеЖµеѓЉиЗіеБПеЈЃгАВ
ж≠§е§ЦпЉМDeepSeekйЗЗзФ®GRPOзЃЧж≥ХпЉМзФ®зїДиѓДеИЖжЫњдї£дЉ†зїЯCriticж®°еЮЛпЉМзЃЧеКЫжґИиАЧйЩНдљО30%дї•дЄКпЉМињЫдЄАж≠•йЩНдљОдЇЖеѓєз°ђдїґиµДжЇРзЪДйЬАж±ВпЉМдєЯе∞±жШѓдњЧзІ∞зЪДеѓєвАЬеН°вАЭзЪДдЊЭиµЦпЉМдЄФж®°еЮЛиГљеКЫдєЯеєґжЬ™еЫ†зЃЧеКЫзЪДйЩНдљОиАМе§ІжЙУжКШжЙ£гАВ
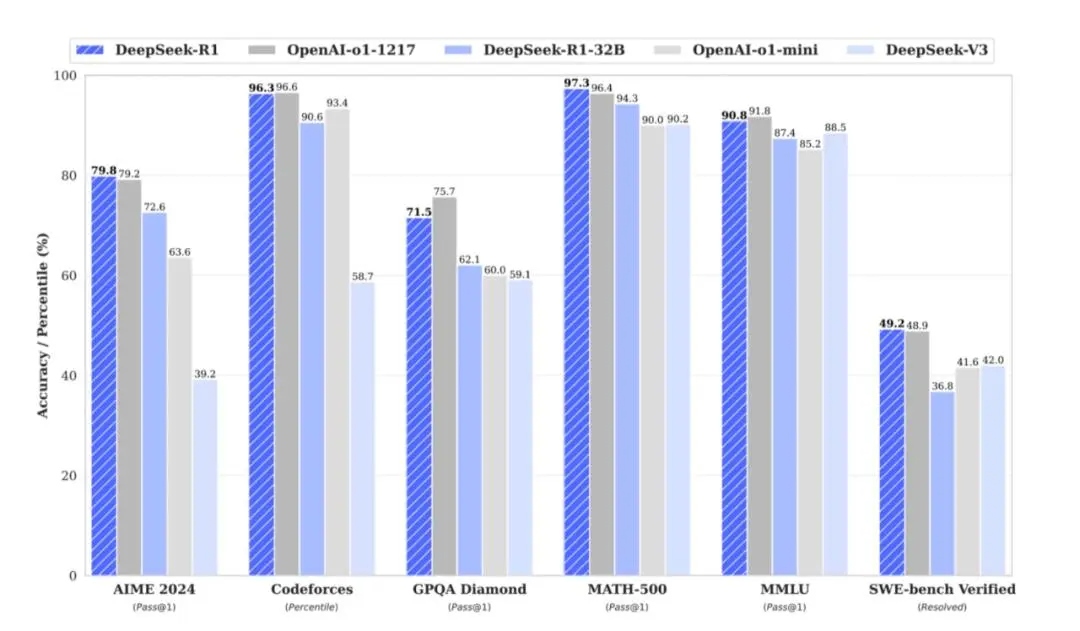
дїОжИРжЬђдЊІжЭ•зЬЛпЉМDeepSeekжПРдЊЫдЇЖдЄАзІНжЫідЄЇйАВйЕНAIиРљеЬ∞зЪДдљОйЧ®жІЫгАБдљОжИРжЬђжЦєеЉПгАВеѓєдЄ≠е§ІдЉБдЄЪдєГиЗ≥е§ЃеЫљдЉБиАМи®АпЉМеПѓдї•зФ®жЫідљОзЪДжИРжЬђињЫи°Ме§Іж®°еЮЛй°єзЫЃзЪДйГ®зљ≤пЉМжИЦиАЕжККйЗНзВєжЫіе§ЪеЬ∞иљђзІїеИ∞жХ∞жНЃж≤їзРЖзОѓиКВпЉМињЫдЄАж≠•жПРйЂШжЬАзїИзЪДж®°еЮЛжХИжЮЬгАВе∞ПеЮЛзІСжКАеЕђеПЄдєЯеРМж†ЈеПЧзЫКпЉМдї•еЊАеЫњдЇОиµДйЗСгАБжКАжЬѓжЧ†ж≥ХжґЙиґ≥зЪДAIйҐЖеЯЯпЉМзО∞еЬ®еЈ≤еЉАеРѓдЇЖеПѓиГљгАВдЉБдЄЪеПѓдї•еИ©зФ®зЫЄеѓєиЊГдљОзЪДжИРжЬђпЉМеЯЇдЇОDeepSeekеЉАеПСеЗЇйАВеРИиЗ™еЈ±дЄЪеК°йЬАж±ВзЪДAIеЇФзФ®пЉМжО®еК®еЕђеПЄдЄЪеК°зЪДеПСе±ХеТМеИЫжЦ∞гАВйЪПзЭАеЉЇеМЦе≠¶дє†пЉИRLпЉЙжКАжЬѓиМГеЉПзЪДеПШйЭ©пЉМжЫіе§ЪдЉБдЄЪеТМеЉАеПСиАЕеЊЧеИ∞дЇЖеПВдЄОAIеИЫжЦ∞зЪДжЬЇдЉЪгАВ
зђђдЇМпЉМеЫ†дЄЇеЉАжЇРеК†йАЯпЉМе±ЮдЇОеЮВзЫіе∞Пж®°еЮЛзЪДжؕ姩жЭ•дЇЖгАВ
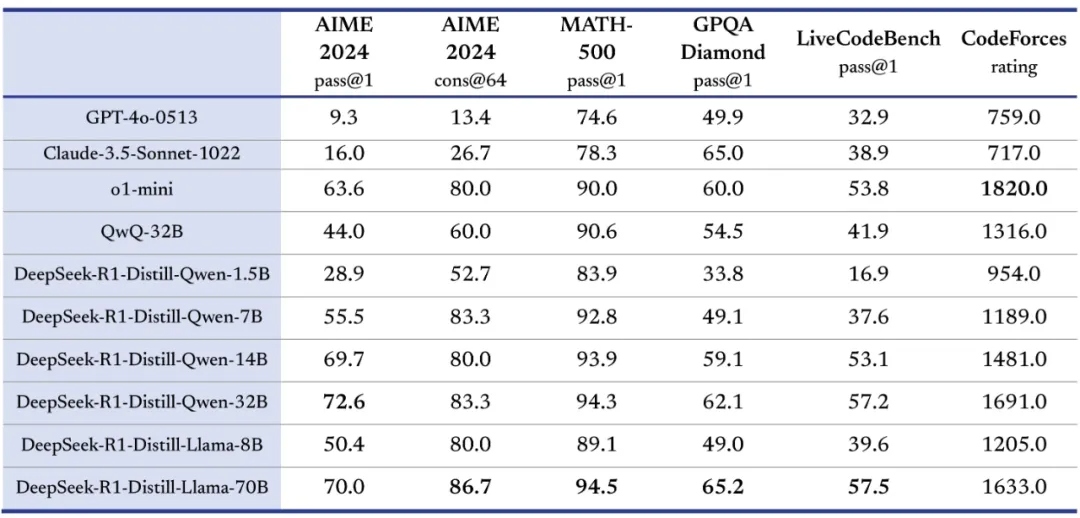
иЈ®зїіеЇ¶зЯ•иѓЖиТЄй¶ПдљУз≥їзЪДжЮДеїЇжШѓDeepSeekзЪДеП¶дЄАе§ІдЇЃзВєгАВдЄАзїДжХ∞жНЃжШЊз§ЇпЉМDeepSeek-R1-Distill-Qwen-7BеЬ®AIME 2024иѓДжµЛдЄ≠дї•55.5%зЪДеЊЧеИЖиґЕиґКеОЯзЙИQwQ-32B-PreviewпЉМеЬ®еПВжХ∞иІДж®°зЉ©еЗП81%зЪДжГЕеЖµдЄЛпЉМжАІиГљжПРеНЗдЇЖ23%гАВеЕґ32BзЙИжЬђжЫіеЬ®MATH-500жµЛиѓХдЄ≠иЊЊеИ∞94.3%зЪДжГКдЇЇеЗЖз°ЃзОЗпЉМиЊГдЉ†зїЯиЃ≠зїГжЦєж≥ХжПРеНЗињС40дЄ™зЩЊеИЖзВєгАВ
ињЩжШѓйАЪињЗе∞Ж32Bе§Іж®°еЮЛзЪДжО®зРЖйАїиЊСиІ£жЮДдЄЇеПѓињБзІїзЪДиЃ§зЯ•ж®°еЉПпЉМеЖНзїПзФ±еК®жАБжЭГйЗНеИЖйЕНжЬЇеИґж≥®еЕ•еИ∞7Bе∞Пж®°еЮЛдЄ≠пЉМеЃЮзО∞дЇЖвАЬжАЭзїіиМГеЉПвАЭиАМйЭЮеНХзЇѓвАЬзЯ•иѓЖиЃ∞ењЖвАЭзЪДдЉ†йАТпЉМзФ®дЉ†зїЯжЦЗеМЦзЪДж¶ВењµжЭ•и°®ињ∞пЉМеН≥зФ±вАЬжЬѓвАЭеЕ•вАЬйБУвАЭпЉМиІ¶еПКеИ∞еПСе±ХжЬђиі®пЉМжПРдЊЫдЇЖжЫійЂШе±Вжђ°зЪДзРЖењµгАВ
еЬ®ињЩзІНжКАжЬѓиЈѓеЊДдЄЛпЉМе∞Пж®°еЮЛдЄНдїЕзїІжЙњдЇЖе§Іж®°еЮЛзЪДиІ£йҐШиГљеКЫпЉМжЫідє†еЊЧдЇЖйЧЃйҐШжЛЖиІ£гАБйАїиЊСжО®жЉФзЪДеЕГиГљеКЫгАВињЩдєЯжДПеС≥зЭАвЉ§еЮЛж®°еЮЛзЪДжО®зРЖж®°еЉПеПѓдї•иТЄй¶ПеИ∞вЉ©еЮЛж®°еЮЛдЄ≠пЉМеЕґжАІиГљдЉШдЇОзЫіжО•еЬ®вЉ©ж®°еЮЛдЄКеЉЇеМЦиЃ≠зїГзЪДзїУжЮЬгАВињЩжШЊзДґжЙУз†ідЇЖжИСдїђвАЬж®°еЮЛиґКе§ІпЉМжАІиГљиґКеЉЇвАЭзЪДеЫЇжЬЙиЃ§зЯ•гАВ
йЪПзЭАињЩзІНвАЬиТЄй¶П+еЉЇеМЦе≠¶дє†вАЭзЪДе§НеРИиЃ≠зїГжЦєеЉПзЪДеЗЇзО∞пЉМе∞Пж®°еЮЛзЪДжؕ姩䊊дєОи¶БжЭ•дЇЖгАВдЄ≠е∞ПеЮЛдЉБдЄЪеТМеЮВзЫійҐЖеЯЯдЄУдЄЪдЉБдЄЪеПѓдї•жШЊиСЧеЗПе∞СеЬ®з°ђдїґиЃЊе§ЗйЗЗиі≠еТМзІЯиµБдЄКзЪДвљАеЗЇпЉМеРМжЧґйЩНдљОиГљжЇРжґИиАЧжИРжЬђгАВ
еЬ®вЉ©ж®°еЮЛжЬЙжХИжАІзЪДиґЛеКњдЄЛпЉМжЛ•жЬЙвЊПдЄЪиЃ§зЯ•зЪДдЉБдЄЪйАЪеЄЄеѓєиЗ™иЇЂдЄЪеК°жµБз®ЛеТМжХ∞жНЃзЙєзВєжЬЙжЈ±еИїзРЖиІ£пЉМеЊАеЊАиГље§ЯжЫіењЂйАЯеЬ∞е∞Жж®°еЮЛйЫЖжИРеИ∞зО∞жЬЙдЄЪеК°з≥їзїЯдЄ≠пЉМиЃ©дЄУдЄЪиГљеКЫжПРеНЗж®°еЮЛеРЂйЗСйЗПпЉМеЬ®AIйҐЖеЯЯеЃЮзО∞ењЂйАЯиґЕиљ¶пЉМжИРдЄЇеЮВзЫіиµЫйБУAIиІДеИЩзЪДеИґеЃЪиАЕеТМеЉХйҐЖиАЕгАВ
зђђдЄЙпЉМзЂѓдЊІеЇФзФ®еН≥е∞ЖињЫеЕ•зИЖеПСжЬЯгАВ
DeepSeekзЪДеЗЇзО∞е∞ЖеЉХиµЈжЦ∞дЄАиљЃзЪДзїИзЂѓеЇФзФ®зИЖеПСпЉМдЄЇеРДи°МдЄЪзЪДжХ∞е≠ЧеМЦиљђеЮЛеТМеНЗзЇІжПРдЊЫжЬЙеКЫзЪДжКАжЬѓжФѓжТСгАВ
еПЧз°ђдїґзЃЧеКЫжЙАйЩРпЉМдєЛеЙНеЬ®жЙЛжЬЇзЂѓгАБеПѓз©њжИіиЃЊе§ЗзЂѓз≠ЙеЊИйЪЊињРи°Ме§ІеЮЛAIж®°еЮЛпЉМдїОиАМйЩРеИґдЇЖAIжКАжЬѓеЬ®ињЩдЇЫйҐЖеЯЯзЪДеЇФзФ®пЉМиАМеЬ®еЃЮжЧґеЖ≥з≠ЦеЬЇжЩѓдЄ≠пЉМAIйЬАж±ВзЪДжї°иґ≥ињШе≠ШеЬ®еЊИе§ІзЉЇеП£гАВ
DeepSeekйАЪињЗж®°еЮЛеОЛзЉ©жКАжЬѓпЉМдљњеЕґдЉШеМЦеРОзЪДж®°еЮЛеПѓдї•жЫіе•љеЬ∞йАВеЇФиµДжЇРжЬЙйЩРзЪДиЃЊе§ЗпЉМињЩдљњеЊЧиЊєзЉШиЃ°зЃЧиЃЊе§ЗиГље§ЯеЕЈе§ЗжЫіеЉЇзЪДAIиГљеКЫпЉМдЄЇзФ®жИЈжПРдЊЫжЫіеК†дЊњжНЈгАБжЩЇиГљзЪДдљУй™МгАВдЊЛе¶ВеЬ®жЩЇиГљзЬЉйХЬдЄ≠пЉМDeepSeekеПѓдї•еЃЮзО∞жЫіењЂйАЯгАБжЫіеЗЖз°ЃзЪДеЫЊеГПиѓЖеИЂеТМиѓ≠йЯ≥дЇ§дЇТеКЯиГљпЉМзФ®жИЈеПѓдї•йАЪињЗжЩЇиГљзЬЉйХЬйЂШжХИиОЈеПЦдњ°жБѓгАБињЫи°МеѓЉиИ™гАБиѓЖеИЂзЙ©дљУз≠ЙпЉМе§Іе§ІжПРеНЗдЇЖжЩЇиГљзЬЉйХЬзЪДеЃЮзФ®жАІеТМеЇФзФ®еЬЇжЩѓгАВ
еЬ®еЃЮжЧґеЖ≥з≠ЦеЬЇжЩѓжЦєйЭҐпЉМйЂШжХИжО®зРЖиГљеКЫиГљеПСжМ•йЗНи¶БдљЬзФ®гАВдї•йЗСиЮНдЇ§жШУдЄЇдЊЛпЉМйЗСиЮНжЬЇжЮДйЬАи¶БеЬ®жЮБзЯ≠зЪДжЧґйЧіеЖЕеѓєе§ІйЗПзЪДеЄВеЬЇжХ∞жНЃињЫи°МеИЖжЮРеТМе§ДзРЖпЉМдї•еБЪеЗЇеЗЖз°ЃзЪДжКХиµДеЖ≥з≠ЦгАВDeepSeekиГље§ЯењЂйАЯеЬ∞еѓєжХ∞жНЃињЫи°МеИЖжЮРеТМйҐДжµЛпЉМдЄЇйЗСиЮНдЇ§жШУжПРдЊЫеЃЮжЧґзЪДеЖ≥з≠ЦжФѓжМБпЉМеЄЃеК©йЗСиЮНжЬЇжЮДжПРйЂШдЇ§жШУжХИзОЗеТМзЫИеИ©иГљеКЫгАВ

зФ®жЫідљОзЪДжИРжЬђеЇФеѓєзЫЄеРМзЪДAIиѓЈж±ВпЉМжИЦзФ®зЫЄеРМзЪДжИРжЬђеЇФеѓєжЫіе§ЪAIиѓЈж±ВпЉМжДПеС≥зЭАдљњзФ®AIзЪДжИРжЬђињШдЉЪињЫдЄАж≠•дЄЛйЩНпЉМзЬЯж≠£жДПдєЙдЄКиЃ©AIжЧ†е§ДдЄНеЬ®пЉМеПѓз©њжИіиЃЊе§Зе∞ЖдЉЪжШѓAIжЩЃжГ†зЪДйЗНи¶БеИЗеП£гАВ
зђђеЫЫпЉМDeepSeekеЄ¶жЭ•дЇЖAIзФЯжАБдЄКзЪДеПШйЭ©пЉМдЄЇAIиРљеЬ∞дЇІдЄЪдњГзФЯжЫіе§ЪеПѓиГљжАІгАВ
ељУеЙНAIдЇІдЄЪеСИзО∞еЗЇдЄАзІНйЗСе≠Че°ФзїУжЮДпЉМOpenAIгАБи∞Јж≠Мз≠ЙеЈ®е§іжККжОІеЯЇз°Аж®°еЮЛпЉМдЄ≠е±ВдЉБдЄЪдЊЭиµЦAPIи∞ГзФ®пЉМйЩЈеЕ•жХ∞жНЃз©ЇењГеМЦпЉМеЇХе±ВдЄ≠е∞ПеЉАеПСиАЕ姱еОїдЇЖдЄїеК®жАІпЉМж≤¶дЄЇзФЯжАБйЩДеЇЄгАВињЩзІНзїУжЮДзЪДиЗіеСљзЉЇйЩЈжШѓеИЫжЦ∞еБЬжїЮпЉМеЈ®е§ідЄЇзїіжМБеЮДжЦ≠пЉМењЕзДґйЩРеИґж®°еЮЛеЉАжФЊеЇ¶гАВ
иАМDeepSeekеЉАжЇРдЇЖж†ЄењГж®°еЮЛпЉМеЉАжФЊдЇЖAPIеЃЪеИґиГљеКЫпЉМжЙУз†ідЇЖдї•еЊАеЈ®е§ідїђдЄїеѓЉзЪДйЗСе≠Че°ФеЉПзФЯжАБгАВ
еЬ®жЦ∞зЪДзФЯжАБж®°еЉПдЄЛпЉМе§ІеОВе∞ПеОВйГљиГљжЙЊеИ∞иЗ™еЈ±йАВеРИзЪДиІТиЙ≤гАВе§ІеОВеПѓдї•дЄУж≥®дЇОзВЉж®°еЮЛпЉМеИ©зФ®еЉЇе§ІзЪДжКАжЬѓеЃЮеКЫеТМиµДжЇРдЉШеКњдЄНжЦ≠дЉШеМЦжПРеНЗж®°еЮЛзЪДжАІиГљеТМиГљеКЫгАВдЄ≠е∞ПеОВеИЩеПѓдї•дЄУж≥®еБЪеЇФзФ®пЉМеЯЇдЇОеЉАжЇРж®°еЮЛењЂйАЯеЉАеПСдЄУзФ®AIеЈ•еЕЈпЉМжЧ†йЬАдЊЭиµЦеЈ®е§іжПРдЊЫвАЬйїСзЃ±вАЭиГљеКЫпЉМеЕЕеИЖеПСжМ•иЗ™иЇЂзЪДзБµжіїжАІеТМеИЫжЦ∞иГљеКЫпЉМеЉАеПСеЗЇжЫіеК†иііињСзФ®жИЈйЬАж±ВеТМи°МдЄЪзЙєзВєзЪДAIеЇФзФ®пЉМдїОиАМиОЈеПЦжЫіе§ЪзЪДеПСе±Хз©ЇйЧіеТМжЬЇдЉЪгАВ
ињЩзІНзФЯжАБеПШйЭ©ињШеЄ¶жЭ•дЇЖжКАжЬѓж∞СдЄїеМЦгАБзФЯжАБж≠£еЊ™зОѓеТМеЬЇжЩѓеЃЪеИґеМЦз≠Йе§ЪжЦєйЭҐзЪДе•ље§ДпЉМдЄНдїЕдЄЇAIдЇІдЄЪзЪДеПСе±ХеЄ¶жЭ•жЦ∞жЬЇйБЗпЉМдєЯдЄЇеРДи°МдЄЪзЪДжХ∞е≠ЧеМЦиљђеЮЛеТМеНЗзЇІжПРдЊЫдЇЖжЦ∞зЪДеК®еКЫгАВ
еЉАжЇРж†ЄењГж°ЖжЮґпЉМеРЄеЉХеЉАеПСиАЕзІѓжЮБеПВдЄОзФЯжАБеїЇиЃЊпЉМж±ЗиБЪеРДжЦєзЪДжЩЇжЕІеТМиµДжЇРпЉМиÚ嚥жИРеЉЇе§ІзЪДжКАжЬѓеРИеКЫгАВеП¶дЄАжЦєйЭҐпЉМиБФеРИиКѓзЙЗеОВеХЖгАБдЇСжЬНеК°еХЖдї•еПКеЮВзЫійҐЖеЯЯзЪДдЄУдЄЪдЉБдЄЪпЉМ嚥жИРвАЬзЃЧеКЫвАФж®°еЮЛвАФеЬЇжЩѓвАЭзЪДйУБдЄЙиІТеРИдљЬж®°еЉПпЉМиГље§ЯдњГињЫдЇІдЄЪйУЊдЄКдЄЛжЄЄзЪДеНПеРМеИЫжЦ∞пЉМжЙУйА†дЄАдЄ™еРИдљЬеű赥зЪДдЇІдЄЪзФЯжАБзОѓеҐГгАВ

дїОељУеЙНзЪДи°МдЄЪ嚥еКњжЭ•зЬЛпЉМе∞љзЃ°дЄ≠еЫљAIе§Іж®°еЮЛеЬ®йАЪзФ®иГљеКЫдЄКжЪВжЧґйЪЊдї•еЕ®йЭҐиґЕиґК OpenAIпЉМдљЖйАЪињЗеЬ®еЮВзЫіеЬЇжЩѓдЄ≠зЪДжЈ±иАХзїЖдљЬдї•еПКзФЯжАБзЪДеЉАжФЊеРИдљЬпЉМеЃМеЕ®жЬЙжЬЇдЉЪеЃЮзО∞еЈЃеЉВеМЦз™БеЫіпЉМиµ∞еЗЇдЄАжЭ°зЛђзЙєзЪДвАЬе∞ПиАМзЊОвАЭдєЛиЈѓпЉМйАЪињЗеЬ®зЙєеЃЪи°МдЄЪзЪДжЈ±еЕ•еЇФзФ®еТМдЉШеМЦпЉМйАРж≠•еРСйАЪзФ®жЩЇиГљйҐЖеЯЯжЄЧйАПеТМжЛУе±ХгАВ
ињЩдЄАеПСе±ХиЈѓеЊДдЄНдїЕиГље§ЯеЕЕеИЖеПСжМ•дЄ≠еЫљеЬ®зЙєеЃЪйҐЖеЯЯзЪДдЇІдЄЪдЉШеКњпЉМињШиГље§ЯдЄЇеЕ®зРГAIдЇІдЄЪзЪДеПСе±ХжПРдЊЫдЄАзІНеЕЈжЬЙдЄ≠еЫљзЙєиЙ≤зЪДеИЫжЦ∞ж®°еЉПеТМиІ£еЖ≥жЦєж°ИпЉМжО®еК®AIжКАжЬѓзЪДе§ЪеЕГеМЦеПСе±ХеТМеЇФзФ®гАВ
зЫЄеЕ≥йУЊжО•пЉЪдЄ≠еЫљеМЇжФѓжМБзЪДеЕґдїЦжФѓдїШжЦєеЉПеРНеНХ
