


ињЩдЄ™жШ•иКВпЉМжЧ†иЃЇдљ†жШѓдЄНжШѓзІСжКАзИ±е•љиАЕпЉМе§Іж¶ВзОЗйГљйАГдЄНињЗеЕ≥дЇОDeepSeekзЪДиµДиЃѓеИЈе±ПгАВ
йЩ§е§ХеЙНе§ЬпЉМDeepSeekеЬ®дЄ≠еЫљеМЇеТМзЊОеЫљеМЇиЛєжЮЬApp StoreеЕНиієж¶ЬдЄКеРМжЧґеЖ≤еИ∞дЇЖдЄЛиљљйЗПзђђдЄАпЉМињЩжШѓеЫљдЇІAppеП≤жЧ†еЙНдЊЛзЪДдљ≥зї©пЉМжЫіжШѓеЬ®еЕ®зРГиМГеЫіеЖЕпЉМй¶Цжђ°жЬЙдЇІеУБиґЕиґКOpenAIзЪДChatGPTгАВ
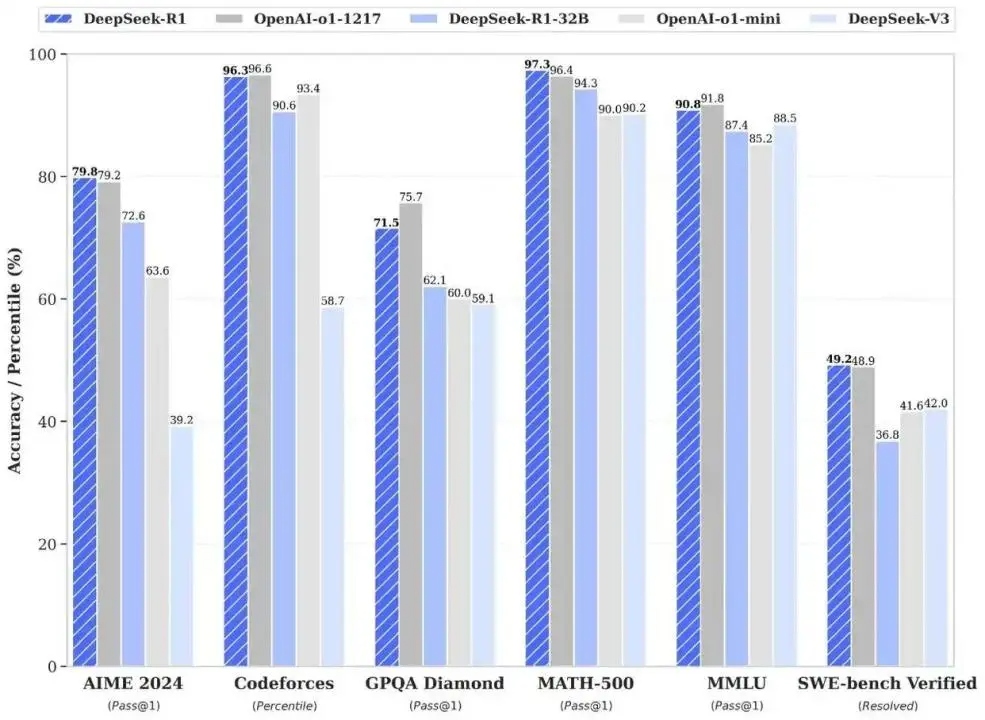
ж≠§еЙНпЉМжЈ±еЇ¶ж±ВзіҐеЃ£еЄГеЕґжО®еЗЇзЪДDeepSeek-V3дїЕиК±иіє558дЄЗзЊОеЕГпЉМдЄНеИ∞еЫље§ЦеЕђеПЄеНБеИЖдєЛдЄАзЪДGPUиКѓзЙЗеТМиЃ≠зїГжЧґйХњпЉМе∞±еЃЮзО∞дЇЖдЄОGPT-4oеТМClaude Sonnet 3.5з≠ЙиК±иієжХ∞дЇњзЊОеЕГиЃ≠зїГзЪДй°ґе∞Цж®°еЮЛзЫЄељУзЪДжАІиГљгАВ1жЬИ20жЧ•пЉМжЈ±еЇ¶ж±В糥жО®еЗЇжО®зРЖж®°еЮЛDeepSeek-R1пЉМдїЕзФ®OpenAIеНБеИЖдєЛдЄАзЪДжИРжЬђе∞±иЊЊеИ∞еЕґжЬАжЦ∞ж®°еЮЛGPT-o1еРМзЇІеИЂзЪДи°®зО∞гАВињЩдЄ™жґИжБѓпЉМдЄНеХїдЇОеЬ®зІСжКАзХМжКХдЄЛдЄАжЮЪйЗНз£ЕзВЄеЉєгАВ

иЗ™дїОAIзЂЮиµЫе≠ШеЬ®дї•жЭ•пЉМињЩжШѓзђђдЄАжђ°пЉМзД¶иЩСзїЩеИ∞зЊОеЫљзІСжКАеЕђеПЄгАВдЄ≠еЫљдЇТиБФзљСеТМзІСжКАеЕђеПЄзЪДиІТиЙ≤еІЛзїИжШѓињљйЪПиАЕпЉМеП™иГљеѓДеЄМжЬЫдЇОзФ®жЫіе§ЪзЪДиµДжЇРжКХеŕ蜚赴僺жЙЛпЉМдљЖй£ОеРСзФ±OpenAIгАБMetaдЄЇдї£и°®зЪДзЊОеЫљеЕђеПЄзЙҐзЙҐжОМжП°гАВ2022еєіиµЈпЉМзЊОеЫљжФњеЇЬеЃ£еЄГеНЗзЇІиКѓзЙЗеЗЇеП£зЃ°еИґпЉМж≠§еРОе§Ъжђ°жЫіжЦ∞еЗЇеП£йЩРеИґжЄЕеНХпЉМйЩРеИґйЂШзЃЧеКЫиКѓзЙЗеЗЇеП£пЉМдЄ≠еЫљAIдЉБдЄЪжЩЃйБНйЩЈеЕ•зЃЧеКЫзД¶иЩСгАВ
DeepSeekжЬАжЦ∞ж®°еЮЛзЪДеЗЇзО∞пЉМжЙУз†ідЇЖе§Іж®°еЮЛеПСе±Хж≤¶дЄЇеЈ®е§ідЄОиµДжЬђжЄЄжИПзЪДи°МдЄЪеЕ±иѓЖпЉМдЄЇдЄЪеЖЕ蜚赴зЊОеЫље§Іж®°еЮЛзЪДдЄ≠еЫљеЕђеПЄдїђжПРдЊЫдЄАжЭ°жЦ∞зЪДжАЭиЈѓпЉМеРСдЄЪзХМиѓБжШОдЇЖеПѓдї•жККе§Іиѓ≠и®Аж®°еЮЛзЪДиЃ≠зїГжИРжЬђйЩНдљО1еИ∞2дЄ™жХ∞йЗПзЇІгАВдЄЪзХМж≠§еЙНжЩЃйБНиЃ§дЄЇзЪДиЃ≠зїГжИРжЬђжШѓ1дЇњзЊОеЕГзФЪиЗ≥жЫіе§ЪпЉМиѓіињЩжШѓдЄАеЬЇвАЬеЖЫе§ЗзЂЮиµЫвАЭеєґдЄНдЄЇињЗгАВеЗ†зЩЊдЄЗзЊОеЕГпЉМдї§дЄЛеЬЇйАРйєњиАЕзЪДйЧ®жІЫдљОдЇЖеЊИе§ЪгАВзО∞еЬ®жѓФжЛЉзЪДпЉМдЄНеЖНеП™жШѓGPUжХ∞йЗПпЉМжЫіеЇФиАГиЩСзЪДжШѓеУ™дЄ™еЫҐйШЯеЕЈе§ЗжКАжЬѓеТМдЇІеУБдЄКзЪДеИЫжЦ∞иГљеКЫгАВ

зЫЄжѓФOpenAIеТМеЃГзЪДдЄ≠еЫљжХИдїњиАЕдїђзФ®жХ∞дЇњзЊОеЕГиЃ≠зїГе§Іж®°еЮЛпЉМDeepSeekйАЙжЛ©дЇЖдЄАжЭ°жЫіжК†йЧ®дєЯжЫіжЮБиЗізЪДиЈѓзЇњгАВ
з†Фз©ґдЇЇеСШжПРеЗЇзЪДдЄАзІНжЦ∞зЪДMLAпЉИе§Ъе§іжљЬеЬ®ж≥®жДПеКЫжЬЇеИґпЉЙжЮґжЮДпЉМдЄОDeepSeek MoESparse (жЈЈеРИдЄУеЃґзїУжЮД)зїУеРИпЉМжККжШЊе≠ШеН†зФ®йЩНеИ∞дЇЖеЕґдїЦе§Іж®°еЮЛжЬАеЄЄзФ®зЪДMHAжЮґжЮДзЪД5%-13%гАВ
и°МдЄЪйАЪеЄЄзФ®жХ∞дЄЗдЇњtokenпЉИжЦЗжЬђеНХдљНпЉЙиЃ≠зїГж®°еЮЛпЉМдљЖDeepSeekйАЪињЗвАЬжХ∞жНЃиТЄй¶ПвАЭжКАжЬѓпЉМеН≥зФ®дЄАдЄ™йЂШз≤ЊеЇ¶зЪДйАЪзФ®е§Іж®°еЮЛељУиАБеЄИпЉМиАМдЄНжШѓзФ®йҐШжµЈжИШжЬѓжЭ•жЫійЂШжХИиЃ≠зїГе≠¶зФЯвАЬж®°еЮЛвАЭпЉМжККжХ∞жНЃиЃ°зЃЧжЬАе§Із®ЛеЇ¶йЩНдљОпЉМдїЕзФ®1/5зЪДжХ∞жНЃйЗПиЊЊеИ∞еРМз≠ЙжХИжЮЬпЉМдњГжИРдЇЖжИРжЬђзЪДдЄЛйЩНгАВ
дЄАдЄ™йАЪдњЧзЪДдЄЊдЊЛеПѓеЄЃеК©жИСдїђзРЖиІ£ињЩзІНеПШеМЦпЉЪдЉ†зїЯе§Іж®°еЮЛжѓПжђ°е§ДзРЖйЧЃйҐШйГљйЬАжњАжіїеЕ®йГ®еПВжХ∞пЉМиАМжЩЃйАЪзФ®жИЈжПРеЗЇзЪДйЧЃйҐШдЄАиИђеєґдЄНйЬАи¶Бе¶Вж≠§е§ІзЪДиµДжЇРжКХеЕ•пЉМињЩе¶ВеРМиЃ©дЄАеЃґеМїйЩҐзЪДеЕ®йГ®зІСеЃ§еОїдЉЪиѓКдЄАдЄ™жЩЃйАЪжДЯеЖТпЉЫиАМDeepSeek-R1дЉЪеЕИеИ§жЦ≠йЧЃйҐШз±їеЮЛпЉМеЖНз≤ЊеЗЖи∞ГзФ®еѓєеЇФж®°еЭЧвАФвАФжХ∞е≠¶йҐШдЇ§зїЩйАїиЊСжО®зРЖеНХеЕГпЉМеЖЩиѓЧеИЩзФ±жЦЗе≠¶ж®°еЭЧе§ДзРЖгАВињЩзІНиЃЊиЃ°иЃ©ж®°еЮЛеУНеЇФйАЯеЇ¶жПРеНЗ3еАНпЉМиГљиАЧдєЯжЫідљОгАВ
жЫіењЂйАЯеЇ¶еТМжЫідљОиГљиАЧпЉМеїЇзЂЛеЬ®вАЬдљОжИРжЬђгАБйЂШжАІиГљвАЭзЪДеИЭеІЛиІДеИТдЄКгАВDeepSeekйАЪињЗзЃЧж≥ХдЉШеМЦжШЊиСЧйЩНдљОиЃ≠зїГжИРжЬђгАВR1зЪДйҐДиЃ≠зїГиієзФ®еП™жЬЙ557.6дЄЗзЊОеЕГпЉМеЬ®2048еЭЧиЛ±дЉЯиЊЊH800 GPUпЉИйТИеѓєдЄ≠еЫљеЄВеЬЇзЪДдљОйЕНзЙИGPUпЉЙйЫЖзЊ§дЄКињРи°М55姩еЃМжИРгАВж≠§еЙНпЉМOpenAIз≠ЙдЉБдЄЪиЃ≠зїГж®°еЮЛпЉМйГљйЬАи¶БжХ∞еНГзФЪиЗ≥дЄКдЄЗеЭЧйЂШзЃЧеКЫзЪДA100гАБH100з≠Йй°ґзЇІжШЊеН°пЉМиК±иієжХ∞дЇњзЊОеЕГзЪДиЃ≠зїГжИРжЬђгАВ
ељУиµДжЇРеПЧеИ∞йЩРеИґжЧґпЉМеЊАеЊАдЉЪжњАеПСеИЫжЦ∞пЉМиАМиµДжЇРињЗдЇОеЕЕж≤ЫпЉМеИЫжЦ∞еНіжЬ™ењЕдЉЪе¶ВжЬЯиАМжЭ•гАВDeepSeekзЪДеЗЇзО∞жШѓеПИдЄАеКЫиѓБгАВ
DeepSeekйАЙжЛ©дїОеЮВзЫіеЬЇжЩѓеИЗеЕ•пЉМдїОall inзЙєеЃЪйҐЖеЯЯеЉАеІЛпЉМињљж±ВеЬ®йГ®еИЖйҐЖеЯЯпЉИе¶ВжХ∞е≠¶гАБдї£з†БпЉЙзЪДи°®зО∞жЫідЉШпЉМеЖНйАРж≠•еИЖйШґжЃµеЃМеЦДеЕґдїЦйҐЖеЯЯзЪДиГљеКЫгАВ
ињЩзІНеП¶иЊЯиєКеЊДдєЯжДПеС≥зЭАжЫійЂШйЪЊеЇ¶пЉМжЫійЂШй£ОйЩ©гАВиЛ•иЈѓзФ±йФЩиѓѓпЉИдЊЛе¶Ве∞ЖиѓЧж≠МеИЫдљЬиѓѓеИ§дЄЇжХ∞е≠¶йҐШпЉЙпЉМиЊУеЗЇиі®йЗПе∞ЖдЉЪжЪіиЈМпЉЫж®°еЭЧйЧізЪДзЯ•иѓЖйЪФз¶їпЉИе¶ВзФ®жХ∞е≠¶еЕђеЉПеЖЩжГЕдє¶пЉЙпЉМеПѓиГљеѓЉиЗіиЈ®йҐЖеЯЯдїїеʰ姱賕гАВе¶ВжЮЬжЬ™иГљеЉАеПСеЗЇиґ≥е§ЯдЉШеЉВзЪДж®°еЭЧеМЦж®°еЮЛпЉМеЙНжЬЯзЪДжКХеЕ•еПѓиГљжµ™иієгАВе§Іе§ЪжХ∞еЕђеПЄеПЧйЩРдЇОиЈѓеЊДдЊЭиµЦжИЦиµДжЇРзЇ¶жЭЯпЉМйЪЊдї•жО•еПЧall inињЩдЄАйЂШй£ОйЩ©иЈѓзЇњгАВиГљжККињЩдЄ™жЮБиЗізЪДиЈѓзЇњиµ∞йАЪпЉМеЛЗж∞ФдЄОиГљеКЫзЉЇдЄАдЄНеПѓгАВ
жЧ©жЬЯDeepSeekзЪДMoEж®°еЮЛиѓѓеИ§зОЗжЩЃйБНеЬ®15%дї•дЄКпЉМеЫҐйШЯйАЪињЗеЉХеЕ•еЉЇеМЦе≠¶дє†дЉШеМЦиЈѓзФ±еЖ≥з≠ЦпЉМйХњжЬЯиЃ≠зїГеРОж®°еЮЛеЬ®жµЛиѓХдЄ≠е∞ЖиѓѓеИ§зОЗжОІеИґеЬ®дЄ™дљНжХ∞зЪДдљОдљНгАВе§ЪдљНи°МдЄЪдЇЇе£Ђе∞ЖDeepSeekзЪДиД±йҐЦиАМеЗЇзРЖиІ£дЄЇвАЬж®°еЭЧеМЦзЙєзІНеЕµвАЭпЉМеЬ®дЄОOpenAIз≠ЙвАЬйАЪзФ®еЈ®еЕљвАЭзЪДжѓФиµЫдЄ≠пЉМеЬ®йГ®еИЖйҐЖеЯЯе±ХзО∞еЗЇеРМз≠ЙиГљеКЫзФЪиЗ≥зХ•еЊЃйҐЖеЕИгАВе∞љзЃ°DeepSeekзЪДжХідљУжКАжЬѓдЄОOpenAIз≠ЙзЊОеЫљдЉБдЄЪе≠ШеЬ®еЈЃиЈЭпЉМдљЖеЕґеЈ≤зїПиґ≥俕襀иІЖдЄЇдЄАдЄ™еЃЮеКЫйАРжЄРжО•ињСзЪДзЂЮдЇЙеѓєжЙЛгАВ
DeepSeekеЉХиµЈиљ∞еК®пЉМйЩ§дЇЖж®°еЮЛжЬђиЇЂзЪДдЉШеЉВи°®зО∞пЉМињШжЭ•иЗ™еЕґеЭЪжМБзЪДеЕНиієеЉАжЇРдЄїеЉ†пЉМеЕђеЉАж®°еЮЛзЪДжЇРдї£з†БгАБжЭГйЗНеТМжЮґжЮДгАВжЧ†иЃЇжШѓдЄ™дЇЇгАБеЉАеПСиАЕпЉМињШжШѓдЉБдЄЪзФ®жИЈпЉМйГљеПѓдї•еЕНиієдљњзФ®еЕґжЬАжЦ∞ж®°еЮЛпЉМеєґеЬ®ж≠§еЯЇз°АдЄКеЉАеПСжЫіе§ЪеЇФзФ®пЉМињЩдєЯеЗЇдЇОDeepSeekеѓєиЗ™иЇЂеПСе±ХжГЕеЖµзЪДиАГйЗПгАВйАЪињЗеЉАжЇРз≠ЦзХ•пЉМеПѓдї•ењЂйАЯеїЇзЂЛзФЯжАБпЉМиОЈеЊЧжЫіе§ЪзФ®жИЈеТМеЉАеПСиАЕжФѓжМБгАВ
еЬ®DeepSeekеИЫеІЛдЇЇжҐБжЦЗйФЛзЬЛжЭ•пЉМDeepSeekжЬ™жЭ•еПѓдї•еП™иіЯиі£еЯЇз°Аж®°еЮЛеТМеЙНж≤њеИЫжЦ∞пЉМеЕґдїЦеЕђеПЄеЬ®DeepSeekзЪДеЯЇз°АдЄКжЮДеїЇTo BгАБTo CзЪДдЄЪеК°пЉМе¶ВжЮЬиÚ嚥жИРеЃМжХізЪДдЇІдЄЪдЄКдЄЛжЄЄпЉМе∞±ж≤°ењЕи¶БиЗ™еЈ±еБЪеЇФзФ®гАВ
DeepSeekзЪДж®°еЭЧеМЦж®°еЮЛиЃЊиЃ°пЉМе¶ВеРМз≤ЊеѓЖзЪДйТЯи°®вАФвАФеНХдЄ™йљњиљЃзЪДеЈ•иЙЇжИЦиЃЄеПѓе§НеИґпЉМдљЖжХідљУеНПеРМйЬАи¶БйХњжЬЯиѓХйФЩдЄОзФЯжАБзІѓзіѓгАВзЂЮдЇЙеѓєжЙЛеєґдЄНиГљдЊЭйЭ†зЃАеНХзЕІжРђе∞±иГље§НеИґеЕґеОЯеІЛж®°еЮЛпЉМиґКе§ЪзФ®жИЈеТМеЉАеПСиАЕдљњзФ®пЉМе∞±жДПеС≥зЭАж®°еЮЛеЊЧеИ∞жЫіе§ЪиЃ≠зїГгАВ
DeepSeekеЬ®еЉХеПСзІСжКАзХМеЈ®йЬЗеРМжЧґпЉМдєЯеЉХзИЖдЇЖдїЈж†ЉжИШгАВжЧ•еЙНпЉМOpenAIеПСеЄГдЇЖеЕ®жЦ∞зЪДo3е§Іж®°еЮЛпЉМеЕНиієеѓєе§ЦеЉАжФЊгАВдЄКеС®еЊЃиљѓдєЯеРСжЙАжЬЙзЪДCopilotзФ®жИЈеЕНиієеПСеЄГдЇЖo1жО®зРЖж®°еЮЛгАВ
еМЧдЇђжЧґйЧі2жЬИ6жЧ•еЗМжЩ®пЉМOpenAIеЃ£еЄГеРСжЙАжЬЙзФ®жИЈеЉАжФЊChatGPTжРЬ糥еКЯиГљпЉМдЄФжЧ†йЬАж≥®еЖМгАВдљњзФ®зХМйЭҐеЊИзЃАеНХпЉМжЙУеЉАвАЬжРЬ糥вАЭжМЙйТЃе∞±и°МпЉМжЧБиЊєзЪДвАЬжО®зРЖвАЭйАЙжЛ©жШѓеР¶е±Хз§ЇжХідЄ™жО®зРЖињЗз®ЛгАВ
и∞Јж≠МDeepMindзЪДGemini 2.0з≥їеИЧеЕ®еЃґж°ґдєЯзїИдЇОж≠£еЉПдЄКжЦ∞пЉМдЄНдїЕеЬ®жАІиГљдЄКжЬЙињЫдЄАж≠•зЪДжПРеНЗпЉМињШжМ•иИЮиµЈAIжАІдїЈжѓФзЪДе§ІжЧЧпЉМеРМжЧґжЛ•жК±е§Ъж®°жАБиГљеКЫгАВ
Gemini 2.0 FlashжФѓжМБе§Ъж®°жАБиЊУеЕ•еТМжЦЗжЬђиЊУеЗЇпЉМеЕЈе§З100дЄЗtokensзЪДдЄКдЄЛжЦЗз™ЧеП£пЉМеєґжФѓжМБзїУжЮДеМЦиЊУеЗЇгАБеЗљжХ∞и∞ГзФ®еТМдї£з†БжЙІи°Мз≠ЙеКЯиГљгАВеЃЪдїЈжЦєж°ИдєЯеЈ≤з°ЃеЃЪпЉМжЦЗжЬђгАБеЫЊеГПеТМиІЖйҐСиЊУеЕ•жѓПзЩЊдЄЗtokensжФґиіє0.10зЊОеЕГпЉМйЯ≥йҐСиЊУеЕ•еИЩдЄЇ0.70зЊОеЕГпЉИ2жЬИ20жЧ•иµЈж≠£еЉПзФЯжХИпЉЙгАВжЦЗжЬђиЊУеЗЇжѓПзЩЊдЄЗtokensжФґиіє0.40зЊОеЕГгАВиљїйЗПзЙИGemini 2.0 Flash-LiteзЪДжЦЗжЬђгАБеЫЊеГПеТМиІЖйҐСиЊУеЕ•жѓПзЩЊдЄЗtokensдїЕйЬА0.075зЊОеЕГпЉМеЗ†дєОжѓФж†ЗеЗЖзЙИдЊњеЃЬдЇЖдЄЙеИЖдєЛдЄАгАВйЯ≥йҐСиЊУеЕ•дєЯдЄЇ0.075зЊОеЕГпЉМжЦЗжЬђиЊУеЗЇдЄЇ0.30зЊОеЕГпЉМжЦЗжЬђ/еЫЊеГП/иІЖйҐСзЉУе≠ШдЄЇжѓПзЩЊдЄЗtokensдїЕйЬА0.01875зЊОеЕГпЉМйЯ≥йҐСзЉУе≠ШдЄЇ0.175зЊОеЕГгАВ

дљЬдЄЇеѓєжѓФпЉМDeepSeek-V3ж®°еЮЛзО∞еЬ®зЪДдїЈж†ЉжШѓжѓПзЩЊдЄЗtokensйЬАи¶Б0.014зЊОеЕГгАВ2жЬИ8жЧ•иµЈпЉМеЕґдїЈж†Ље∞ЖжБҐе§НеИ∞жѓПзЩЊдЄЗtokens 0.07зЊОеЕГзЪДж∞іеє≥гАВињЩдЄАи∞ГжХіжИЦиЃЄдєЯжШѓдњГдљњGoogleеИґеЃЪељУеЙНдїЈж†Љз≠ЦзХ•зЪДйЗНи¶БеЫ†зі†дєЛдЄАгАВ
DeepSeekзЪДжИРеКЯжЙУз†ідЇЖдєЛеЙНеЫљеЖЕзІСжКАйҐЖеЯЯеѓєдЇОе§Іиѓ≠и®Аж®°еЮЛзЪДжЧҐеЃЪеПСе±ХиМГеЉПпЉМжО•дЄЛжЭ•ињШдЉЪеЉХеПСдЄАз≥їеИЧжґЯжЉ™жХИеЇФгАВ
дїК姩зЪДAIзЂЮдЇЙж†Ље±АдєЛдЄЛпЉМеѓєдЇОдЄАеЃґеИЫдЄЪеЕђеПЄпЉМеЉАжЇРдЄНдїЕжШѓжКАжЬѓз≠ЦзХ•пЉМжЫіжШѓеПВдЄОеИґеЃЪи°МдЄЪиІДеИЩзЪДеЕ≥йФЃиРље≠РгАВеЬ®ж®°еЮЛиГљеКЫйАРжЄРйАПжШОзЪДжЬ™жЭ•пЉМзЬЯж≠£зЪДзЂЮдЇЙдЉШеКње∞ЖжЭ•иЗ™жЮДеїЇжХ∞жНЃеПНй¶ИйЧ≠зОѓзЪДиГљеКЫпЉМдї•еПКе∞ЖжКАжЬѓељ±еУНеКЫиљђеМЦдЄЇеХЖдЄЪзФЯжАБзЪДиГљеКЫгАВе••зЙєжЫЉеЬ®RedditдЄКжПРеИ∞пЉМи¶Бе≠¶дє†DeepSeekпЉМе∞ЖжО®зРЖж®°еЮЛзЪДжАЭиАГињЗз®ЛеЕђеЉАгАВOpenAIзЪДйЧ≠жЇРз≠ЦзХ•дљњдїЦдїђзЂЩеИ∞дЇЖеОЖеП≤йФЩиѓѓзЪДдЄАиЊєпЉМдїЦдїђе∞ЖйЗНжЦ∞жАЭиАГOpenAIзЪДеЉАжЇРз≠ЦзХ•пЉМеРМжЧґдїЦеЭ¶и®АOpenAIзЪДйҐЖеЕИдЉШеКњеЈ≤зїПдЄНе¶ВдєЛеЙНе§ІдЇЖгАВ
ињЩжЬђиі®дЄКжШѓдЄАеЬЇеЕ≥дЇОвАЬж†ЗеЗЖеИґеЃЪжЭГвАЭзЪДдЇЙе§ЇвАФвАФи∞БзЪДеЉАжЇРеНПиЃЃиГљжИРдЄЇи°МдЄЪдЇЛеЃЮж†ЗеЗЖпЉМи∞Бе∞±иГљеЬ®дЄЛдЄАдї£AIеЯЇз°АиЃЊжЦљдЄ≠еН†жНЃж†ЄењГдљНзљЃгАВдЄ≠еЫљзІСжКАеЕђеПЄдЄОзЊОеЫљзІСжКАеЕђеПЄдєЛйЧізЪДеЈЃиЈЭпЉМдЄНжШѓжЧґйЧізїіеЇ¶пЉМиАМжШѓеИЫжЦ∞еТМж®°дїњзЪДеЈЃеИЂгАВ
зЫЄеЕ≥йУЊжО•пЉЪдЄ≠еЫљеМЇжФѓжМБзЪДеЕґдїЦжФѓдїШжЦєеЉПеРНеНХ
