


жЧґйЪФдњ©жЬИпЉМDeepSeekзїИдЇОжЫіжЦ∞дЇЖгАВ
3жЬИ24жЧ•жЩЪпЉМDeepSeekдЄАе£∞дЄНеР≠еЊАHugging FaceдЄКжЙФдЇЖдЄ™DeepSeek-V3-0324ж®°еЮЛпЉМж®°еЮЛеПВжХ∞6850дЇњпЉМдЄОдЄКдЄАдЄ™зЙИжЬђV3зЪД6710дЇњзЫЄеЈЃдЄНе§ІпЉМйЗЗзФ®MoEжЮґжЮДпЉМињШжФѓжМБдЇЖжЫіеЉАжФЊзЪДMITеЉАжЇРеНПиЃЃгАВ
ж†єжНЃеЃШжЦєжЫіжЦ∞зЪДзЙИжЬђиѓіжШОпЉМDeepSeek-V3-0324дЄїи¶БжШѓйТИеѓєжО®зРЖиГљеКЫеТМеЙНзЂѓеЉАеПСиГљеКЫињЫи°МдЇЖеК†еЉЇпЉМеЖЩдљЬй£Ож†ЉеЃЮзО∞дЇЖиЈЯR1еѓєйљРпЉМеП¶е§ЦињШжЬЙдЄАдЇЫеЕґдїЦжЦєйЭҐзЪДе∞ПдЉШеМЦгАВзО∞еЬ®еП™и¶БжЙУеЉАDeepSeekеЃШзљСпЉМжККжЈ±еЇ¶жАЭиАГж®°еЉПеЕ≥жОЙе∞±иГљзЫіжО•зФ®дЄКV3-0324гАВ

иЩљзДґињЩдЄ™дЄЊжО™зЬЛиµЈжЭ•еП™жШѓDeepSeek V3зЪДдЄАдЄ™е∞ПеНЗзЇІпЉМдљЖдљОи∞ГдЄНдї£и°®ж≤°жЬЙеПНеУНгАВV3-0324еИЪдЄКзЇњпЉМе∞±зЩїдЄКдЇЖHugging FaceзЪДиґЛеКњж¶ЬеНХпЉМеЉХиµЈдЄЪеЖЕиљ∞еК®пЉМдљУй™МињЗзЪДзљСеПЛиѓіеЃГзЪДдї£з†БиГљеКЫеЈ≤зїПзЫіињљClaudeгАВдЊЛе¶ВиЃ©V3-0324зФЯжИРдЄАдЄ™зљСй°µпЉМж®°еЮЛдЄАеП£ж∞ФеЖЩдЇЖ800е§Ъи°Мдї£з†БпЉМињРи°МзЪДжЧґеАЩињШж≤°жЬЙеЗЇйФЩпЉМињЩеЃЮеКЫе∞±дЄНзФ®е§ЪиѓідЇЖеРІпЉЯжЬЙдЇЇдїЕдїЕдЄЛиЊЊдЇЖзЉЦеЖЩзЩїељХй°µйЭҐзЪДзЃАеНХжМЗдї§пЉМеєґж≤°жЬЙдїїдљХеЕґдїЦзЪДйЩДеК†жПРз§ЇпЉМV3-0324еРМж†ЈдєЯзФЯжИРдЇЖдЄАдЄ™еЃМжХізЪДзЩїељХй°µйЭҐпЉМжѓФиµЈV3зФЯжИРзЪДвАЬдєЮдЄРзЙИвАЭпЉМзЫЄеОїдЄНеПѓдї•жѓЂеОШиЃ°гАВ
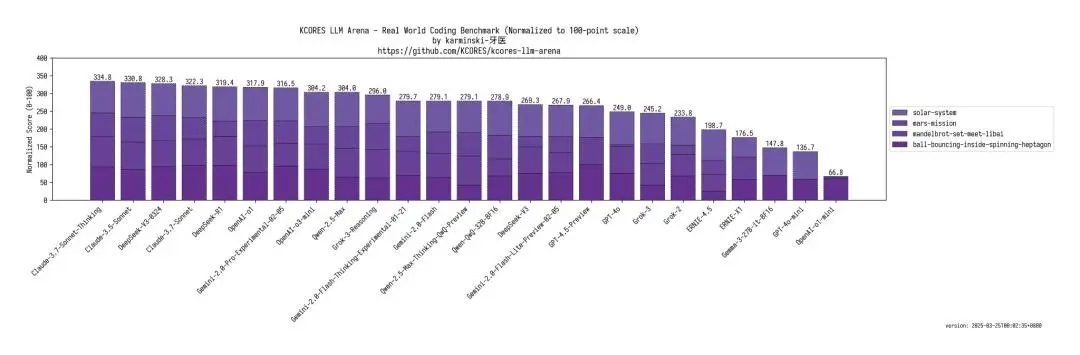
еЬ®еЫље§Це§Іж®°еЮЛзЂЮжКАеЬЇKCORESзЪДжµЛиѓДдЄ≠пЉМV3-0324зЪДдї£з†БиГљеКЫеЊЧеИЖдЄЇ328.3пЉМиґЕињЗдЇЖжЩЃйАЪзЙИзЪДClaude 3.7 SonnetзЪД322.3еИЖпЉМжО•ињСClaude 3.7 SonnetжАЭзїійУЊзЙИжЬђзЪД334.8еИЖпЉМжОТеРНзђђдЄЙгАВињЩдЄ™жОТи°Мж¶ЬдЄКеЙНеЗ†еРНзЪДж®°еЮЛе∞±еЗ†дєОж≤°жЬЙеЉАжЇРзЪДпЉМDeepSeekеЬ®еЕґдЄ≠дЄАжЮЭзЛђзІАгАВ
DeepSeek-V3-0324йЭҐдЄЦжЧґж≤°жЬЙйЩДеЄ¶зЩљзЪЃдє¶пЉМдєЯж≤°жЬЙдїїдљХеЃ£дЉ†пЉМеП™жЬЙдЄАдЄ™з©ЇзЪДReadMeжЦЗдїґгАВињЩдЄАињСдєОжЬізі†зЪДеПСеЄГ嚥еЉПпЉМдЄОз°Еи∞Јж®°еЮЛйЭҐеЄВжЧґзЪДз≤ЊењГз≠ЦеИТињ•еЉВгАВ3жЬИ25жЧ•жЩЪдЄКпЉМDeepSeekеЃШжЦєзїИдЇОеПСжЦЗж≠£еЉПдїЛзїНдЇЖињЩж≥Ґе∞ПжЫіжЦ∞пЉМеЬ®жХ∞е≠¶гАБдї£з†Бз±їзЪДзЫЄеЕ≥иѓДжµЛдЄКпЉМV3-0324жѓФOpenAIзЫЃеЙНжЬАеОЙеЃ≥зЪДйЭЮжО®зРЖж®°еЮЛGPT-4.5йГљи¶БжЫіиГЬдЄАз≠єгАВдљУй™МињЗзЪДзљСеПЛзЫіеСЉињЩжђ°зЪДжЫіжЦ∞иґЕеЗЇйҐДжЬЯе§Ъе§ЪпЉМе∞§еЕґеЬ®зЉЦз®ЛжЦєйЭҐпЉМжШѓзЫЃеЙНжЬАеЉЇе§ІдЄФеЃМеЕ®еЕНиієзЪДAIгАВиАМжЬАе•љеХЖдЄЪж®°еЮЛдєЛдЄАзЪДClaude SonnetеИЩи¶БжМЙжЬИжФґеПЦ20зЊОеЕГзЪДиієзФ®гАВ
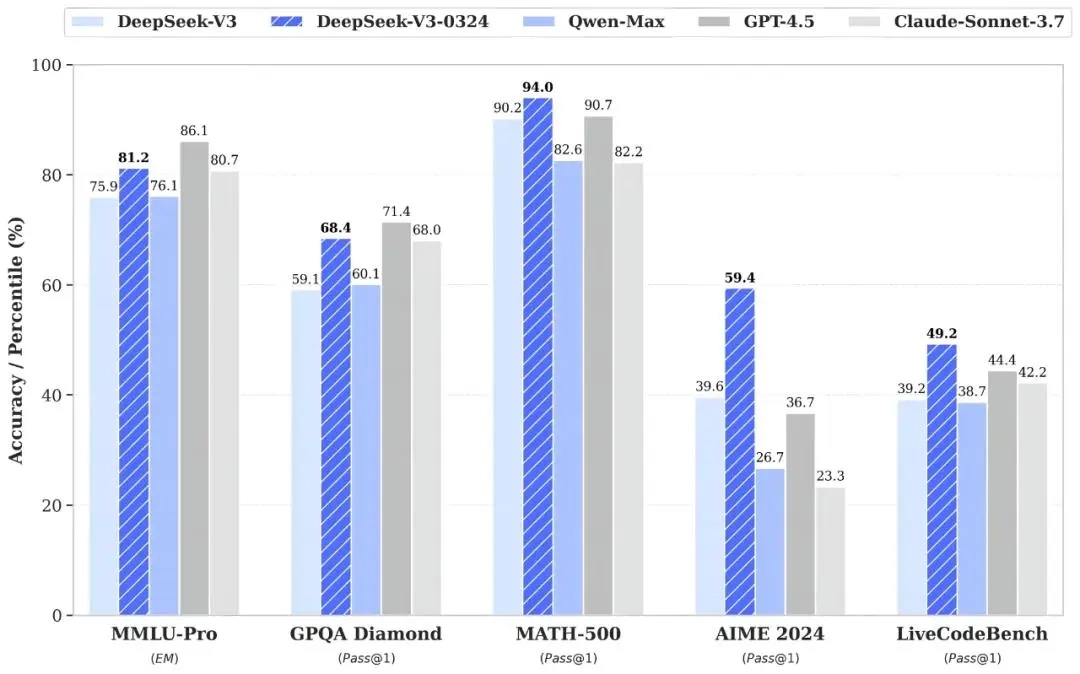
зїПжµЛиѓХпЉМDeepSeek-V3-0324зЪДеРДжЦєйЭҐиГљеКЫпЉМеЈ≤зїПеПѓдї•еТМClaude 3.7 SonnetжО∞дЄАжО∞жЙЛиЕХгАВдїОжАІдїЈжѓФжЦєйЭҐзЬЛжЭ•пЉМOpenAIзЪДo1-proеТМGPT-4.5йГљеЈ≤зїПдЄНй¶ЩдЇЖгАВеЬ®еЉАжЇРињЩдЄ™иµЫйБУдЄКпЉМDeepSeekзЪДзЂЮдЇЙеКЫжѓЛеЇЄзљЃзЦСгАВ
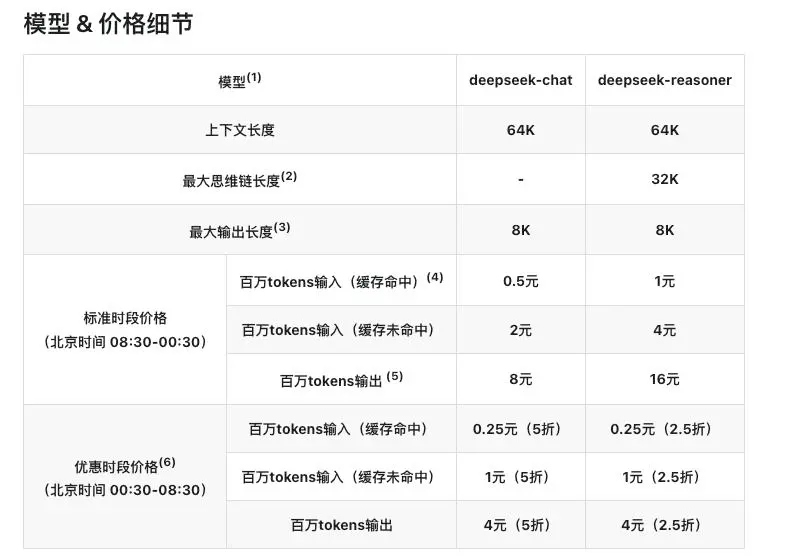
DeepSeekзЪДAPIдїЈж†ЉдєЯдЄїжЙУдЄАдЄ™дЊњеЃЬгАВV3-0324зЩЊдЄЗtokensиЊУеЕ•зЪДдїЈж†ЉжШѓ2еЕГпЉМиЊУеЗЇзЪДдїЈж†ЉжШѓ8еЕГпЉМиАМеРМж†ЈзЪДtokensжХ∞пЉМClaude 3.7 SonnetзЪДиЊУеЕ•еТМиЊУеЗЇдїЈж†ЉеИЖеИЂжШѓ36.6еЕГеТМ108.9еЕГпЉМдїЈеЈЃжЬАе§ЪиЊЊ18еАНгАВ
DeepSeekзЪДињРи°МжЦєеЉПдєЯж†Ље§ЦвАЬзОѓдњЭвАЭгАВеЃГдїОж†єжЬђдЄКйЗНжЦ∞жЮДжГ≥дЇЖе§ІеЮЛиѓ≠и®Аж®°еЮЛзЪДињРдљЬжЦєеЉПпЉМеЬ®зЙєеЃЪдїїеК°жЬЯйЧідїЕжњАжіїзЇ¶370дЇњдЄ™еПВжХ∞иАМйЭЮеЕ®йГ®пЉМдєЯе∞±жШѓжЙАи∞УзЪДвАЬдЄУеЃґвАЭж®°еЭЧпЉМињЩе§Іе§ІйЩНдљОдЇЖиЃ°зЃЧйЬАж±ВгАВ
иѓ•ж®°еЮЛињШжЬЙеП¶е§ЦдЄ§й°єз™Бз†іжАІжКАжЬѓпЉЪе§Ъе§іжљЬеЬ®ж≥®жДПеКЫ(MLA)еТМе§Ъж†ЗиЃ∞йҐДжµЛ(MTP)гАВMLAеҐЮеЉЇдЇЖж®°еЮЛеЬ®йХњзѓЗжЦЗжЬђдЄ≠дњЭжМБдЄКдЄЛжЦЗзЪДиГљеКЫпЉМMTPжѓПдЄАж≠•зФЯжИРе§ЪдЄ™ж†ЗиЃ∞пЉМиАМдЄНжШѓйАЪеЄЄзЪДдЄАжђ°зФЯжИРдЄАдЄ™ж†ЗиЃ∞пЉМињЩдЄ§иАЕеЕ±еРМе∞ЖиЊУеЗЇйАЯеЇ¶жПРйЂШдЇЖињС80%гАВ

жЯРзІНз®ЛеЇ¶дЄКпЉМDeepSeekдљУзО∞дЇЖдЄ≠еЫљдЉБдЄЪеѓєжХИзОЗеТМиµДжЇРжЮБиЗіињљж±ВзЪДз≤Њз•ЮпЉМеН≥е¶ВдљХдї•жЬЙйЩРзЪДиЃ°зЃЧиµДжЇРеЃЮзО∞зЫЄз≠ЙжИЦиАЕжЫіеК†дЉШеМЦзЪДжАІиГљпЉМињЩзІНзФ±йЬАж±Вй©±еК®зЪДеИЫжЦ∞еЈ≤зїПдљњдЄ≠еЫљзЪДдЇЇеЈ•жЩЇиГљеЬ®еЗ†дЄ™жЬИжЧґйЧіеЖЕйЬЗжГКдЇЖеЕ®зРГпЉМдЄОдЄЦзХМй°ґе∞ЦеѓєжЙЛзЪДиЈЭз¶їдЄНжЦ≠еЬ®зЉ©зЯ≠гАВ
зДґиАМе∞±еЬ®DeepSeekжЫіжЦ∞еРОдЄНеИ∞30е∞ПжЧґпЉМи∞Јж≠МжЬАжЦ∞ж®°еЮЛGemini 2.5 ProеЃЮй™МзЙИжЬђдєЯжЈ±е§ЬдЄКзЇњдЇЖгАВињЩдЄАж®°еЮЛеЬ®е§Ъй°єеЯЇеЗЖжµЛиѓХдЄ≠еЕ®йЭҐиґЕиґКOpenAI o3-miniгАБClaude 3.7 SonnetгАБGrok-3еТМDeepSeek-R1пЉМдЄАзїПдЇЃзЫЄдЊњеЬ®е§Іж®°еЮЛзЂЮжКАеЬЇиОЈеЊЧ1443еИЖпЉМиАМдЄФеИЫдЄЛдЇЖеОЖеП≤жЬАе§ІеИЖжХ∞й£ЮиЈГпЉМеЗ≠еАЯ39еИЖзЪДе§ІеєЕдЉШеКњпЉМиОЈеЊЧжЦ≠е±ВзђђдЄАгАВ
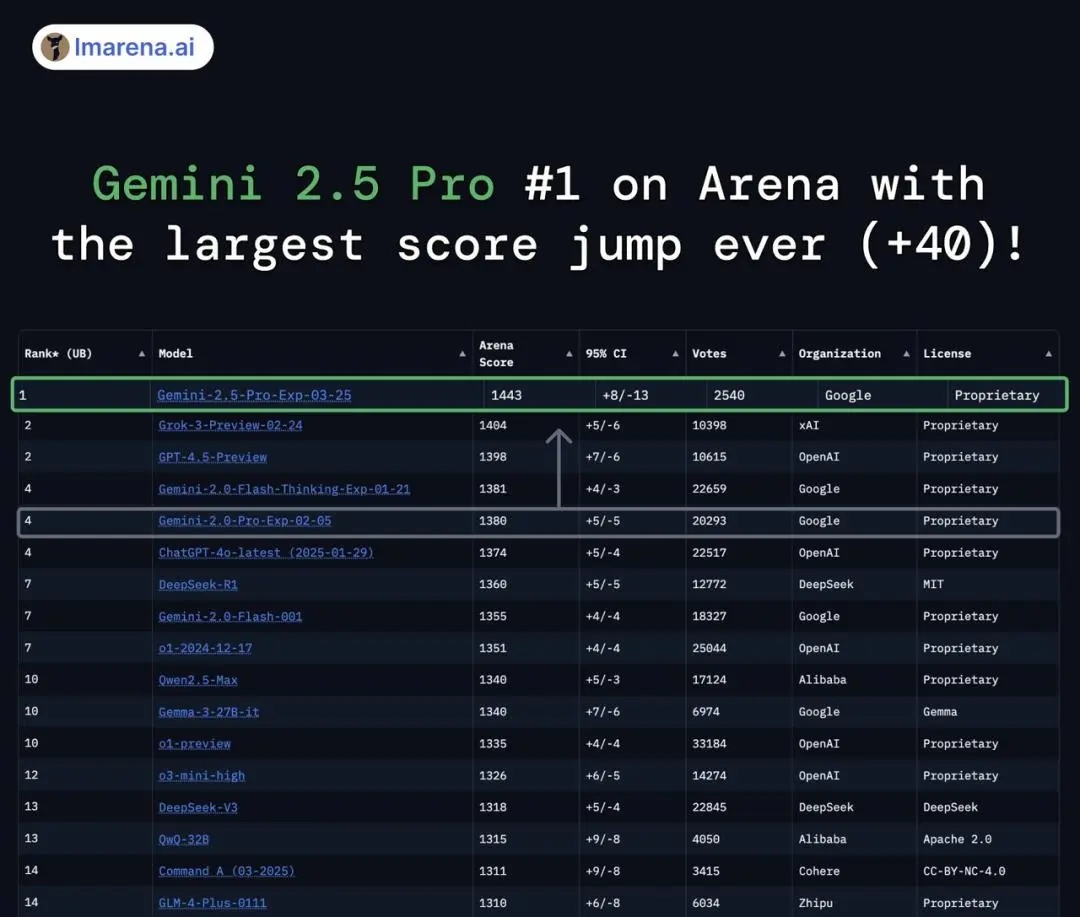
и∞Јж≠МеЃ£зІ∞пЉМињЩжШѓдЄАдЄ™вАЬжАЭиАГвАЭж®°еЮЛпЉМеЃГжШѓдЄЦзХМдЄКжЬАеЉЇе§ІзЪДж®°еЮЛпЉМеЕЈе§ЗзїЯдЄАзЪДжО®зРЖиГљеКЫпЉМдї•еПКзФ®жИЈжЙАеЦЬзИ±зЪДGeminiзЪДжЙАжЬЙеКЯиГљпЉИйХњдЄКдЄЛжЦЗгАБеЈ•еЕЈз≠ЙпЉЙгАВж≠§и®АйЭЮиЩЪпЉМGemini 2.5 ProеЬ®е§ЪдЄ™еЯЇеЗЖжµЛиѓХдЄ≠иЊЊеИ∞дЇЖSOTAпЉИState-of-the-ArtпЉМеН≥ељУдЄЛжЬАеЕИињЫпЉЙж∞іеє≥пЉМе∞§еЕґеЬ®жО®зРЖеТМзЉЦз†БдЄКжЫіжШѓйҐЖеЕИдЄАж≠•гАВ
и∞Јж≠Ми°®з§ЇпЉМеЬ®AIйҐЖеЯЯпЉМз≥їзїЯзЪДвАЬжО®зРЖвАЭиГљеКЫдЄНдїЕдїЕжМЗеИЖз±їеТМйҐДжµЛпЉМиАМжШѓжМЗз≥їзїЯеИЖжЮРдњ°жБѓгАБеЊЧеЗЇйАїиЊСзїУиЃЇгАБиЮНеЕ•дЄКдЄЛжЦЗеТМзїЖеЊЃеЈЃеИЂпЉМдї•еПКеБЪеЗЇжШОжЩЇеЖ≥з≠ЦзЪДиГљеКЫгАВ
йХњжЬЯдї•жЭ•пЉМи∞Јж≠МдЄАзЫіеЬ®жΥ糥йАЪињЗеЉЇеМЦе≠¶дє†еТМжАЭзїійУЊжПРз§ЇиѓНз≠ЙжКАжЬѓпЉМиЃ©AIжЫіжЩЇиГљгАБжЫіеЕЈжО®зРЖиГљеКЫзЪДжЦєж≥ХгАВ

ж≠£жШѓеЬ®ж≠§еЯЇз°АдЄКпЉМдїЦдїђеЬ®2жЬИжО®еЗЇдЇЖзђђдЄАдЄ™жАЭиАГж®°еЮЛпЉМGemini 2.0 Flash ThinkingпЉМеЃГиГље§ЯињЫи°Ме§Ъж≠•жО®зРЖпЉМеєґиЃ©зФ®жИЈеЃЮжЧґињљиЄ™еЃГзЪДжО®зРЖињЗз®ЛгАВ
иАМзО∞еЬ®пЉМйАЪињЗGemini 2.5пЉМдїЦдїђзїУеРИдЇЖжШЊиСЧеҐЮеЉЇзЪДеЯЇз°Аж®°еЮЛеТМжФєињЫзЪДеРОжЬЯиЃ≠зїГпЉМиЃ©ж®°еЮЛиЊЊеИ∞дЇЖжЦ∞зЪДжАІиГљж∞іеє≥гАВGemini 2.5 ProзЪДж†ЄењГеИЫжЦ∞еЬ®дЇОжККжО®зРЖдљЬдЄЇз≥їзїЯеЇХе±ВиГљеКЫжЭ•жЮДеїЇпЉМж®°еЮЛиГље§ЯеЬ®еЕЕеИЖжАЭиАГеТМжЭГи°°дєЛеРОжЙНзїЩеЗЇиІ£еЖ≥жЦєж°ИгАВ
зЫЄиЊГдЇОеП™жККжО®зРЖељУдљЬвАЬе§ЦжМВвАЭзЪДеБЪж≥ХпЉМињЩзІНеЕ®жЦєдљНзЪДжХіеРИиЃ©ж®°еЮЛеЬ®еЫЮе§НжЧґжЫіеЗЖз°ЃгАБжЫіиііињСзЬЯеЃЮеЬЇжЩѓпЉМдєЯжЫіиГљжНХжНЙзФ®жИЈзЪДдЄКдЄЛжЦЗеРЂдєЙеТМзїЖеЊЃеЈЃеЉВгАВдЇЛеЃЮиѓБжШОпЉМињЩзІНиљђеПШз°ЃеЃЮе§ІеєЕжПРеНЗдЇЖж®°еЮЛзЪДи°®зО∞гАВ
еЬ®и∞Јж≠МиЗ™еЃґзЪДе§Ъй°єиѓДдЉ∞дЄ≠пЉМGemini 2.5 ProеПЦеЊЧдЇЖжЮБдЄЇжКҐзЬЉзЪДжИРзї©пЉЪ
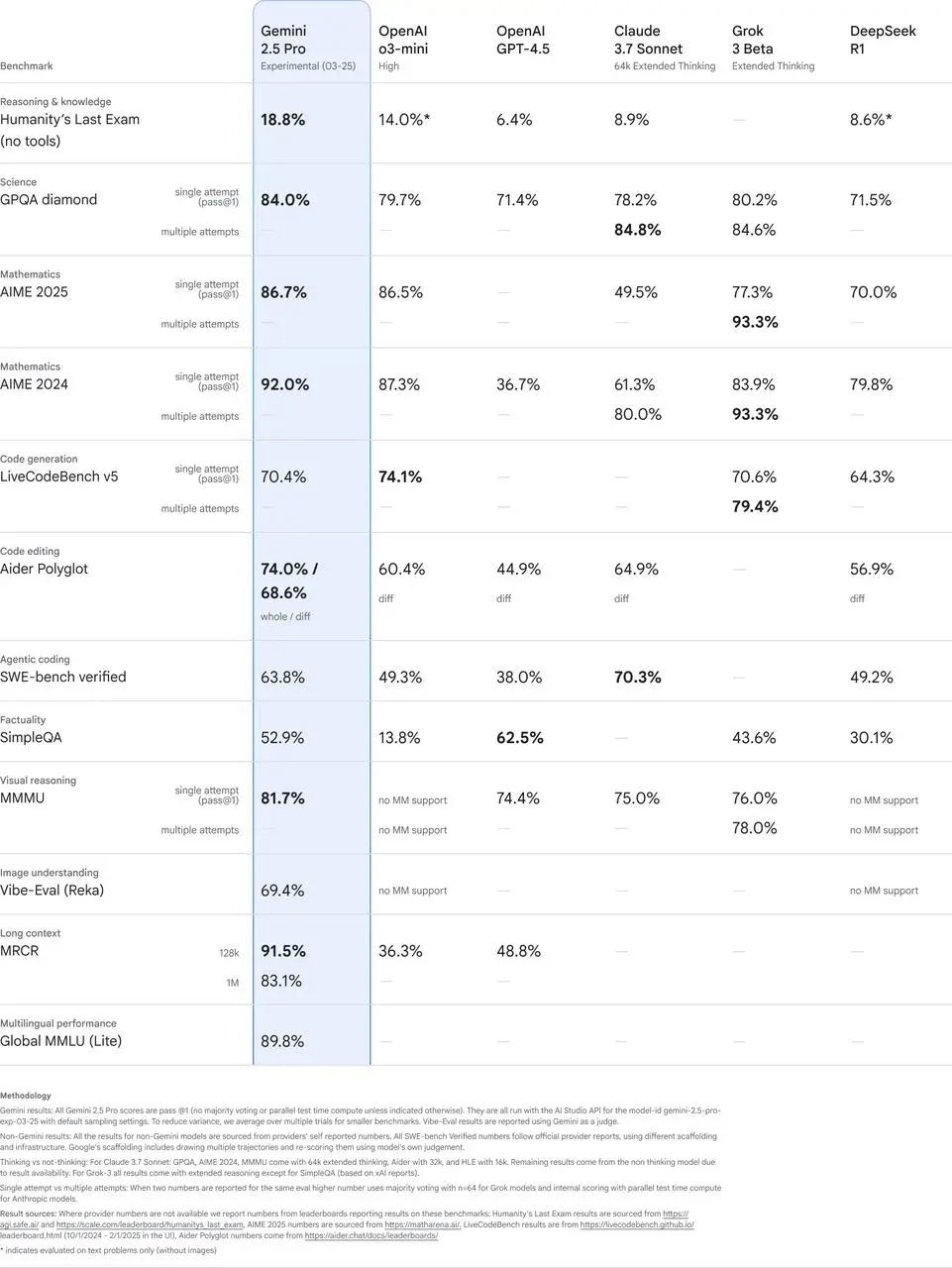
еЬ®йЂШеЇ¶е§НжЭВзЪДжО®зРЖеЯЇеЗЖдЄКз®≥е±Еж¶Ьй¶ЦпЉМеєґдЄФжЧ†йЬАдЊЭиµЦжШВиіµзЪДжКХз•®жИЦеЕґдїЦеПШйАЪжЙЛжЃµгАВ
еЬ®GPQAдЄОAIME 2025з≠ЙеЯЇеЗЖдЄ≠йГљйҐЖеЕИдЇОеРМз±їдЇІеУБгАВ
йЭҐеѓєйЪЊеЇ¶жЮБйЂШзЪДHumanityвАЩs Last ExamпЉИдЇЇз±їжЬАеРОиАГиѓХпЉМзФ±жХ∞зЩЊеРНдЄУеЃґжЮДеїЇпЉМзФ®жЭ•жµЛиѓХдЇЇз±їзЯ•иѓЖеТМжО®зРЖжЮБйЩРпЉЙињЩдЄАеЯЇеЗЖжµЛиѓХпЉМжЫіжШѓжЛњдЄЛдЇЖ18.8%зЪДдЉШеЉВжИРзї©пЉМиАМдЄФеЕ®з®ЛжЬ™еАЯеК©дїїдљХеЈ•еЕЈиЊЕеК©гАВдЄОOpenAI o3-miniзЫЄжѓФпЉМеЕґеЊЧеИЖжПРеНЗдЇЖињС5%пЉМжПРеНЗжѓФдЊЛиЊЊ34%гАВ
зЉЦз†БиГљеКЫзЪДй£ЮиЈГеРМж†ЈеАЉеЊЧдЄАжПРгАВзЫЄжѓФGemini 2.0пЉМ2.5 ProеЬ®жЮДеїЇWebеЇФзФ®гАБзЉЦеЖЩдї£зРЖеЉПдї£з†Бдї•еПКињЫи°Мдї£з†БиљђжНҐз≠ЙдїїеК°дЄКйГљжЬЙйЗНе§Із™Бз†ігАВеЬ®SWE-Bench VerifiedпЉИдЄУйЧ®зФ®жЭ•и°°йЗПдї£зРЖзЉЦз†Бж∞іеє≥зЪДеЯЇеЗЖпЉЙдЄ≠пЉМжЫіжШѓйЭ†зЭАеЃЪеИґдї£зРЖйЕНзљЃеПЦеЊЧдЇЖ63.8%зЪДи°®зО∞гАВ
жѓФе¶ВеЬ®дЄЛйЭҐињЩдЄ™demoдЄ≠пЉМдїЕдїЕж†єжНЃињЩи°МpromptпЉМеЃГе∞±зФЯжИРдЇЖдЄАжЃµp5jsзЪДдЇ§дЇТеЉПеК®зФїпЉМе±Хз§ЇдЇЖвАЬеЃЗеЃЩй±ЉвАЭзЪДеЬЇжЩѓпЉМеєґдЄФињШжШЊз§ЇдЇЖй±ЉдїђйГљеЬ®жГ≥дїАдєИгАВ

и∞Јж≠МеЬ®жИШиГЬиЗ™еЈ±зЪДиЈѓдЄКиµ∞еЊЧиґКжЭ•иґКињЬгАВGemini 2.5 ProжИРдЄЇй¶ЦдЄ™еЃЮеКЫе™≤зЊОClaude 3.5 SonnetзЪДж®°еЮЛпЉМзЫЄжѓФдєЛеЙНзЙИжЬђзЪДGeminiжЫіжШѓеЃЮзО∞дЇЖиі®зЪДй£ЮиЈГгАВеЃГзїІжЙњеєґеПСжЙђдЇЖGeminiж®°еЮЛзЪДдЉШеКњвАФвАФеОЯзФЯе§Ъж®°жАБиГљеКЫеТМиґЕйХњдЄКдЄЛжЦЗйХњеЇ¶гАВиЗ™еПСеЄГдєЛеИЭпЉМ2.5 Proе∞±жФѓжМБ100дЄЗtokensзЪДдЄКдЄЛжЦЗз™ЧеП£пЉИ200дЄЗtokensдєЯеН≥е∞ЖжО®еЗЇпЉЙпЉМжАІиГљжШЊиСЧиґЕиґКдЇЖеЙНдї£ж®°еЮЛгАВињЩиГљиЃ©еЃГзРЖиІ£жµЈйЗПжХ∞жНЃйЫЖпЉМеєґе§ДзРЖжЭ•иЗ™е§ЪзІНдњ°жБѓжЇРзЪДе§НжЭВйЧЃйҐШпЉМеМЕжЛђжЦЗжЬђгАБйЯ≥йҐСгАБеЫЊеГПгАБиІЖйҐСпЉМзФЪиЗ≥еЃМжХізЪДдї£з†БдїУеЇУгАВ
зЫЃеЙНпЉМGemini 2.5 ProеЈ≤еЬ®Google AI StudioеТМGeminiеЇФзФ®дЄ≠еРСGemini AdvancedзФ®жИЈеЉАжФЊпЉМеєґе∞ЖеЊИењЂеЬ®Vertex AIдЄКжО®еЗЇгАВеЃГзЪДеЃЪдїЈжЦєж°ИдЉЪеЬ®жЬ™жЭ•еЗ†еС®еЖЕеЕђеЄГпЉМзФ®жИЈеПѓдї•еЬ®жЫійЂШдљњзФ®йЕНйҐЭдЄЛпЉМе∞Жж®°еЮЛеЇФзФ®дЇОе§ІиІДж®°зФЯдЇІзОѓеҐГгАВзїПзљСеПЛеЃЮжµЛпЉМеЃГзЪДеЃЮеКЫз°Ѓе¶ВдЉ†иѓідЄ≠дЄАж†ЈжГКдЇЇпЉМеЬ®жЙАжЬЙж®°еЮЛдЄ≠жХИжЮЬжЛФзЊ§пЉМзђђдЄАжђ°е∞ЭиѓХе∞±еП™зФ®еЗ†зІТиІ£еЖ≥дЇЖдЄАйБУйЪЊйҐШгАВ

Gemini 2.5зЪДеПСеЄГпЉМжДПеС≥зЭАи∞Јж≠МеЬ®ињИеРСвАЬжЩЇиГљдї£зРЖжЧґдї£вАЭдЄКеПИеРСеЙНжО®ињЫдЇЖдЄАе§Іж≠•гАВжЬ™жЭ•жЙАжЬЙGemini 2.5з≥їеИЧж®°еЮЛйГље∞ЖйЫЖжИРињЩзІНвАЬеЄ¶жЬЙжАЭиАГиГљеКЫвАЭзЪДзїУжЮДпЉМиГље§ЯиЗ™дЄїзРЖиІ£е§НжЭВжГЕеҐГеєґжЙІи°МзЫЄеЇФдїїеК°гАВ
е§Іж®°еЮЛеНЈеИ∞дїК姩пЉМдї•жИСдїђзЪДзЬЉеЕЙдЄОжГ≥и±°еКЫпЉМеЈ≤зїПеЊИйЪЊйҐДжµЛињЩиВ°жµ™жљЃжЬАзїИдЉЪе•ФзЭАеУ™дЄ™жЦєеРСеОїгАВеЗ†еЃґе§ійГ®дЉБдЄЪзЪДзЂЮдЇЙдЄНжЦ≠еНЗжЄ©пЉМдЄЇAIйҐЖеЯЯеЄ¶жЭ•дЇЖжЫіжњАзГИзЪДеИЫжЦ∞дЄОжЫідЄ∞еѓМзЪДжКАжЬѓйАЙжЛ©пЉМзЫЄдњ°жЬАзїИеПЧзЫКзЪДпЉМдєЯдЉЪжШѓеєње§ІзФ®жИЈгАВ
зЫЄеЕ≥йУЊжО•пЉЪдЄ≠еЫљеМЇжФѓжМБзЪДеЕґдїЦжФѓдїШжЦєеЉПеРНеНХ
