


8жЬИ5жЧ•ж≥®еЃЪдЉЪжИРдЄЇAIжКАжЬѓеТМеХЖдЄЪзЂЮдЇЙж†Ље±АжЉФеПШйЗМзЪДйЗНи¶БжЧґеИїгАВ
ињЩдЄА姩пЉМз°Еи∞ЈжЬАйЗНи¶БзЪДдЄЙеЃґж®°еЮЛе§ІеОВйГљеПСеЄГдЇЖеРДиЗ™йЭЮеЄЄеЕЈжЬЙиКВзВєжДПдєЙзЪДж®°еЮЛпЉМињЩзІНзЫЫеЖµжЬЙйШµе≠Рж≤°иІБеИ∞дЇЖгАВ
еЕИжШѓи∞Јж≠МеПСеЄГдЇЖGenie 3ж®°еЮЛвАФвАФдЄАдЄ™дљ†еПѓдї•еТМж®°еЮЛзФЯжИРзЪД3DдЄЦзХМеЃЮжЧґдЇ§дЇТзЪДдЄЦзХМж®°еЮЛгАВжО•зЭАAnthropicжЫіжЦ∞дЇЖеЃГжЬАдЄїеКЫзЪДClaude Opusз≥їеИЧпЉМеПСеЄГClaude 4.1 OpusпЉМзЉЦз†БиГљеКЫзїІзї≠з™Бз†ігАВзДґеРОOpenAIйҐДеСКдЇЖиЃЄдєЕзЪДеЉАжЇРж®°еЮЛдєЯзїИдЇОжЭ•дЇЖпЉМж≠£е¶Вж≠§еЙНж≥ДйЬ≤зЪДпЉМOpenAIеПСеЄГдЇЖеРНдЄЇGPT-ossгАБеЉАжФЊжЭГйЗНзЪДж®°еЮЛпЉИеРЂ120bгАБ20bдЄ§дЄ™зЙИжЬђпЉЙгАВињЩжШѓеЃГзїІ2019еєі11жЬИеЉАжЇРGPT-2дєЛеРОпЉМеЖНеЇ¶еЉАжЇРеЃГзЪДиѓ≠и®Аж®°еЮЛгАВ
дЄЙдЄ™ж®°еЮЛеПСеЄГеЬ®24е∞ПжЧґеЖЕжО•ињЮеПСзФЯпЉМдљЖдЄОињЗеОїеЕЕжї°зБЂиНѓеС≥зЪДзЫіжО•зЂЮдЇЙдЄНеРМпЉМињЩжђ°еРДеЃґжЫіе§ЪжШѓеЬ®еРДиЗ™жУЕйХњзЪДйҐЖеЯЯе±Хз§ЇдЄНеРМзЪДињЫеМЦжЦєеРСгАВAIзЪДеПЩдЇЛпЉМж≠£еЬ®дїОвАЬи∞БжЫіеЉЇвАЭзЪДеНХдЄАзїіеЇ¶пЉМиµ∞еРСжЫіе§НжЭВе§ЪеЕГзЪДзЂЮдЇЙж†Ље±АгАВ

еОЖеП≤зЬЯжШѓиЃљеИЇгАВOpenAIзЪДеРНзІ∞жЭ•жЇРпЉМе∞±жШѓвАЬеЉАжФЊвАЭгАБвАЬеЉАжЇРвАЭпЉМињЩжی襀еЕґCEOе••зЙєжЫЉиЗ™иѓ©дЄЇAIжЧґдї£зЪДж†ЄењГз≤Њз•ЮеТМзФЯе≠ШдєЛйБУгАВдљЖдїО2019еєіеИЭеЉАеІЛпЉМOpenAIе∞±е§ДењГзІѓиЩСеЬ∞еБПз¶їдЇЖеЉАжЇРиљ®йБУпЉЪйВ£еєі2жЬИпЉМеЃГдї•вАЬеЃЙеЕ®йЧЃйҐШвАЭдЄЇеАЯеП£пЉМжЛТзїЭеЕђеЄГGPT-2зЪДеЕ®йГ®еПВжХ∞жЭГйЗНпЉМеП™еЕђеЄГдЇЖдЄАдЄ™7.74дЇњеПВжХ∞зЪДвАЬйГ®еИЖж®°еЮЛвАЭгАВзЫіеИ∞ељУеєі11жЬИпЉМеЬ®GPT-2дєПдЇЇйЧЃжі•зЪДжГЕеЖµдЄЛпЉМеЃГжЙНзЊЮзЊЮз≠Фз≠ФеЬ∞еЕђеЄГдЇЖеЕ®йГ®15дЇњеПВжХ∞гАВиЗ≥дЇОеРОжЭ•е§ІжФЊеЉВељ©зЪДGPT-3гАБGPT-3.5дї•еПКGPT-4з≥їеИЧе§Іж®°еЮЛпЉМеИЩжЧҐж≤°жЬЙеЕђеЄГињЗеПВжХ∞жЭГйЗНпЉМдєЯж≤°жЬЙеЕђеЄГињЗжКАжЬѓиЈѓзЇњзЩљзЪЃдє¶гАВжИ™ж≠Ґ8жЬИ5жЧ•еЙНпЉМOpenAIеЈ≤жИРдЄЇељУдїКеЕ®зРГAIе§Іж®°еЮЛеЯЇз°Аз†ФеПСзђђдЄАйЫЖеЫҐељУдЄ≠пЉМеѓ•еѓ•еЗ†еЃґвАЬж≤°жЬЙдїїдљХжЦ∞зЙИеЉАжЇРе§Іж®°еЮЛвАЭзЪДеЉАеПСиАЕдєЛдЄАгАВ
ињЩжђ°OpenAIзїИдЇОдЇ§еЗЇдЇЖеЃГзЪДеЉАжФЊжЭГйЗНж®°еЮЛдљЬдЄЪпЉЪGPT-ossпЉМдЄАдЄ™13BеПВжХ∞зЪДеѓЖйЫЖж®°еЮЛгАВеАЉеЊЧж≥®жДПзЪДжШѓпЉМињЩеєґйЭЮдЄАдЄ™иГљдЄОGPT-4oжИЦClaude 4.1еМєжХМзЪДSOTAж®°еЮЛпЉМеЕґжАІиГље§ІиЗіеѓєж†ЗLlama 3-8BжИЦQwen2-7BгАВеЬ®дЄАдЇЫеЯЇеЗЖжµЛиѓХдЄКпЉМеЃГзЪДи°®зО∞зФЪиЗ≥зХ•йАКдЇОеРМйЗПзЇІеѓєжЙЛгАВ
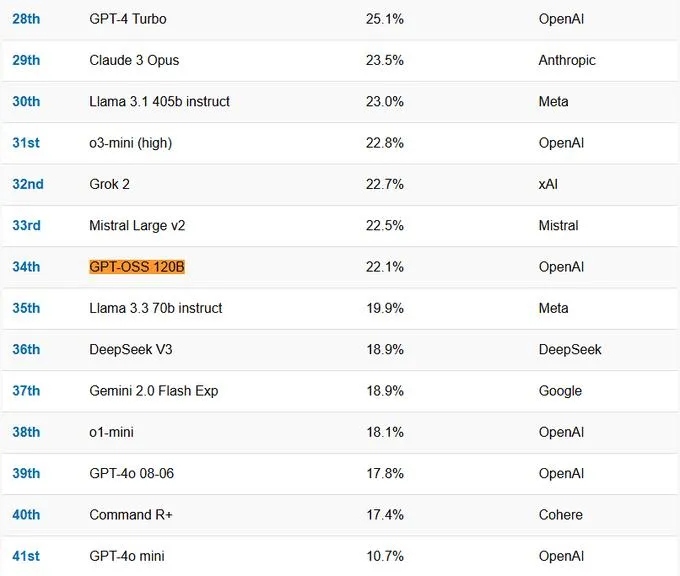
е••зЙєжЫЉзІ∞пЉМGPT-ossжАІиГљдЄОo4-miniж∞іеє≥зЫЄељУгАВеЬ®е§Ъй°єеЯЇеЗЖжµЛиѓХдЄ≠пЉМGPT-oss-120bзЪДи°®зО∞з°ЃеЃЮдЄОOpenAI o4-miniеЗ†дєОжМБеє≥пЉМGPT-oss-20bеИЩдЄОOpenAI o3-miniзЫЄдЉЉгАВ
GPT-ossзЪДжЬАе§ІдЇЃзВєжШѓеЕґйГ®зљ≤зЪДйЂШжХИжАІгАВGPT-oss-120bиГље§ЯеЬ®еНХдЄ™80GB GPUдЄКйЂШжХИињРи°МпЉМдЊЛе¶ВйЂШзЂѓзђФиЃ∞жЬђпЉЫGPT-oss-20bеИЩеП™йЬА16GBеЖЕе≠ШеН≥еПѓеЬ®иЊєзЉШиЃЊе§ЗпЉИдЊЛе¶ВжЙЛжЬЇгАБеє≥жЭњпЉЙдЄКињРи°МпЉМйЭЮеЄЄйАВеРИжЬђеЬ∞жО®зРЖгАБиЃЊе§ЗзЂѓдљњзФ®жИЦеЬ®ж≤°жЬЙйЂШжШВеЯЇз°АиЃЊжЦљзЪДжГЕеЖµдЄЛењЂйАЯињ≠дї£гАВдЄ§жђЊж®°еЮЛеЭЗйЗЗзФ®MXFP4еОЯзФЯйЗПеМЦпЉМеЕґдЄ≠пЉМGPT-oss-120bеЬ®H100 GPUдЄКеОЖзїП210дЄЗеН°жЧґиЃ≠зїГиАМжИРпЉМ20bзЙИжЬђзЪДиЃ≠зїГзФ®йЗПдЄЇеЙНиАЕзЪД1/10гАВ

дљЖGPT-ossзЪДжДПдєЙеєґдЄНеЬ®дЇОжАІиГљпЉМиАМеЬ®дЇОвАЬOpenAIвАЭињЩдЄ™еРНе≠ЧеТМеЃГйЩДеЄ¶зЪДиЃЄеПѓиѓБгАВ
й¶ЦеЕИпЉМињЩдЄНжШѓдЄАжђ°ељїеЇХзЪДеЉАжЇРгАВ
ињЩдЄ§жђЊж®°еЮЛе±ЮдЇОвАЬе±АйГ®еЉАжФЊвАЭзЪДе§Іиѓ≠и®Аж®°еЮЛпЉМеЕђеЄГзЪДеП™жШѓжЭГйЗНгАБдЄАдїљ34й°µзЪДжКАжЬѓзЩљзЪЃдє¶пЉМдї•еПКеЕґдїЦе∞СйЗПйАЙжЛ©жАІзЪДдњ°жБѓгАВеЉЇеМЦе≠¶дє†зЪДжКАжЬѓзїЖиКВгАБйҐДиЃ≠зїГзЪДжХ∞жНЃжЮДжИРгАБжХ∞жНЃжЭ•жЇРз≠Йдњ°жБѓйГљжЬ™жКЂйЬ≤гАВдїЕеЗ≠ињЩдЇЫеЕђеЉАдњ°жБѓпЉМжИСдїђжШѓж≤°ж≥ХвАЬе§НеИґвАЭеЗЇдЄАдЄ™жИРеУБжЭ•зЪДгАВељУзДґељТж†єеИ∞еЇХпЉМе§ІеЃґеПСеЄГеЉАжЇРе§Іж®°еЮЛжШѓдЄЇдЇЖжї°иґ≥йГ®еИЖеЃҐжИЈзЪДйЬАж±ВгАБеЯєиВ≤еЉАеПСиАЕзФЯжАБпЉМиАМдЄНжШѓжЦєдЊњеИЂдЇЇжКДиҐ≠гАВ
GPT-ossдљњзФ®зЪДиЃЄеПѓиѓБжШѓOpenAIиЗ™еЃЪдєЙзЪДвАЬOpenAI Model License 1.0вАЭпЉМеЕґдЄ≠жЬАеЕ≥йФЃзЪДжЭ°жђЊжШѓпЉЪз¶Бж≠ҐдїїдљХеєіеЇ¶жФґеЕ•иґЕињЗ1дЇњзЊОеЕГжИЦжЧ•жіїиЈГзФ®жИЈиґЕињЗ100дЄЗзЪДеХЖдЄЪеЃЮдљУпЉМдљњзФ®GPT-ossжЭ•еЉАеПСжИЦжПРдЊЫдЄОOpenAIж†ЄењГдЇІеУБпЉИе¶ВAPIгАБChatGPTпЉЙзЂЮдЇЙзЪДжЬНеК°гАВињЩдЄ™жЭ°жђЊе∞±з≤ЊеЗЖеЬ∞е∞ЖжЙАжЬЙжљЬеЬ®зЪДе§ІеЕђеПЄзЂЮдЇЙеѓєжЙЛжОТйЩ§еЬ®е§ЦпЉМеРМжЧґеПИиГљиЃ©еєње§ІзЪДдЄ≠е∞ПеЉАеПСиАЕеТМз†Фз©ґиАЕињЫеЕ•еЕґзФЯжАБгАВ
еЕґжђ°пЉМињЩжШѓOpenAIиЗ™GPT-2дї•жЭ•й¶Цжђ°еЉАжФЊжЭГйЗНпЉМжШѓдЄАжђ°йЗНе§ІзЪДжИШзХ•иљђеРСгАВ

еПѓдї•иѓіOpenAIеПСеЄГеЉАжЇРж®°еЮЛпЉМдЄАдЄ™еЊИдЄїи¶БзЪДеОЯеЫ†жШѓDeepSeekзЪДеЖ≤еЗїгАВељУдЄАдЄ™еЕНиієзЪДеЉАжЇРзЪДж®°еЮЛпЉМиЊЊеИ∞дЇЖеЕґеЃГйЧ≠жЇРгАБжФґиієжЮБйЂШзЪДж®°еЮЛеѓєдЇОе§ІйГ®еИЖзФ®жИЈжЭ•иѓіжЙАиГљжДЯеПЧеИ∞зЪДж∞іеЗЖпЉМињЩе∞±жШѓиЗіеСљжЙУеЗїгАВGPT-ossжШЊзДґжШѓOpenAIзЪДдЄАзІНйШ≤еЊ°пЉМдєЯжШѓеЃГжГ≥и¶БеБЪзЪДзФЯжАБжЙ©еЉ†еК®дљЬпЉМеѓєжКЧDeepSeekгАБQwenз≠ЙеЉАжЇРеКЫйЗПеѓєеЕґеЉАеПСиАЕеЯЇз°АзЪДдЊµиЪАгАВ
ељУеЙНеЕ®зРГAIеЄВеЬЇзЂЮдЇЙжњАзГИпЉМжЦ∞еЕіеКЫйЗПеіЫиµЈињЕйАЯпЉМеЬ®ињЩж†ЈзЪДзОѓеҐГдЄЛеЉАжЇРжИРдЄЇйЗНи¶БжЙЛжЃµпЉМеПѓдї•еРЄеЉХжЫіе§ЪеЉАеПСиАЕпЉМеЃМеЦДеЕґзФЯжАБз≥їзїЯгАВ
еѓєзЂЮдЇЙеѓєжЙЛжЭ•иѓіпЉМеЉАжЇРељУзДґжШѓе•љдЇЛпЉМдЊњдЇОдЇТзЫЄе≠¶дє†еАЯйЙіпЉИдї•еПКжКДиҐ≠пЉЙгАВеѓєдЇОеЕ®дЇЇз±їжЭ•иѓіпЉМеЉАжЇРе∞±жЫіжШѓе•љдЇЛпЉМеЫ†дЄЇеОЖеП≤дЄАеЖНиѓБжШОеЉАжФЊиГљдњГињЫжКАжЬѓињЫж≠•гАВдљЖжШѓеѓєдЇОOpenAIињЩзІНеРЄеЉХеИ∞дЄЪзХМжЙАжЬЙзЫЃеЕЙзЪДAIйҐЖе§ізЊКжЭ•иѓіпЉМиЃ©жЫіе§ЪзЪДеЉАеПСиАЕеК†еЕ•еИ∞еЃГзЪДзФЯжАБз≥їзїЯдЄ≠пЉМжЬЙдїАдєИеЃЮйЩЕжДПдєЙпЉЯ

з≠Фж°ИеЊИжШОз°ЃпЉЪеЉАжЇРе§Іж®°еЮЛеПѓдї•дЄЛиљљеЃЙи£ЕеИ∞жЬђеЬ∞з°ђдїґиЃЊе§ЗйЗМпЉМеЃМеЕ®дїОжЬђеЬ∞ињРи°МпЉМињЩеѓєдЇОдЄАйГ®еИЖеЃҐжИЈзЫЄељУжЬЙеРЄеЉХеКЫгАВеЃҐжИЈеПѓдї•жККжЙАжЬЙжХ∞жНЃе≠ШеВ®еЬ®жЬђеЬ∞пЉМиАМдЄНжШѓдЄКдЉ†еИ∞зђђдЄЙжЦєеє≥еП∞пЉМдїОиАМжЬАе§ІйЩРеЇ¶еЬ∞дњЭжК§дЇЖжХ∞жНЃеЃЙеЕ®гАВжЧ†иЃЇеѓєдЇОеЫљеЃґжЬЇеѓЖињШжШѓеХЖдЄЪжЬЇеѓЖжЭ•иѓіпЉМињЩзІНеЃЙеЕ®жАІйГљеЊИйЗНи¶БгАВ
еЃҐжИЈеПѓдї•еЯЇдЇОиЗ™иЇЂйЬАж±ВпЉМеѓєеЉАжЇРе§Іж®°еЮЛињЫи°МеЊЃи∞Г(fine-tune)пЉМдїОиАМе•СеРИзЙєеЃЪи°МдЄЪеЇФзФ®еЬЇжЩѓгАВеМїзЦЧгАБйЗСиЮНз≠Йе§НжЭВжИЦжХПжДЯи°МдЄЪеѓєж≠§йЬАж±Ве∞§еЕґжЧЇзЫЫгАВ
еѓєдЇОйҐДзЃЧжЬЙйЩРзЪДеЃҐжИЈжЭ•иѓіпЉМеЬ®жЬђеЬ∞з°ђдїґдЄКињРи°Ме§Іж®°еЮЛпЉМжИЦиЃЄжѓФиі≠дє∞йЧ≠жЇРе§Іж®°еЮЛдљњзФ®жЭГжЫіеИТзЃЧгАВељУзДґпЉМеЬ®жЬђеЬ∞йГ®зљ≤еЉАжЇРе§Іж®°еЮЛпЉМе∞±жДПеС≥зЭАеЃҐжИЈи¶БдЄЇиЗ™еЈ±зЪДдњ°жБѓеЃЙеЕ®еТМжКАжЬѓзїіжК§иіЯиі£гАВеЬ®жЭГи°°еИ©еЉКдєЛеРОпЉМиЃЄе§Ъе§ІеЮЛи°МдЄЪеЃҐжИЈињШжШѓдЉЪжЫіеБПе•љеЉАжЇРе§Іж®°еЮЛгАВињЩе∞±жШѓLLaMAз≥їеИЧе§Іж®°еЮЛеЬ®жђІзЊОжЈ±еПЧе§ІдЉБдЄЪ搥ињОзЪДеОЯеЫ†пЉМдєЯжШѓDeepSeekеЬ®дїКеєіеєіеИЭеЄ≠еНЈеЫљеЖЕжФњдЉБеЃҐжИЈзЪДеОЯеЫ†гАВDeepSeekзЪДжКАжЬѓж∞іеє≥жИЦиЃЄиГљдЄОGPT-4o1зЫЄжѓФпЉМдљЖе¶ВжЮЬдЄНжШѓеЉАжЇРпЉМеЃГзЪДеЇФзФ®йАЯеЇ¶дЉЪйЭЮеЄЄжЕҐпЉМжЧ†иЃЇеѓєBзЂѓињШжШѓCзЂѓйГљжШѓе¶Вж≠§гАВ
ињЩжђ°OpenAIиµ∞дЄЛз•ЮеЭЫпЉМдЄНеЖНжЙЃжЉФйВ£дЄ™йЂШйЂШеЬ®дЄКзЪДйЧ≠жЇРйҐЖеѓЉиАЕпЉМиАМжШѓиѓХеЫЊйАЪињЗдЄАдЄ™вАЬе§ЯзФ®вАЭзЪДеЉАжФЊж®°еЮЛпЉМе∞ЖеЉАеПСиАЕеРЄеЉХеИ∞еЃГзЪДзФЯжАБз≥їзїЯдЄ≠вАФвАФзФ®GPT-ossињЫи°МжЬђеЬ∞еЉАеПСгАБеЊЃи∞ГпЉМзДґеРОжЧ†зЉЭињБзІїеИ∞жЫіеЉЇе§ІзЪДOpenAIйЧ≠жЇРж®°еЮЛдЄКгАВGPT-ossзЪДиІДж®°дЄОжАІиГљпЉМжБ∞жБ∞жПРдЊЫдЇЖињЩж†ЈдЄАдЄ™з≤ЊжШОзЪДвАЬеН°дљНвАЭгАВзЫЃеЙНпЉМGPT-oss-120bеТМGPT-oss-20bеЈ≤дЄКзЇњеЉАжЇРжЙШзЃ°еє≥еП∞Hugging FaceпЉМжЩЃйАЪзФ®жИЈеИЩеПѓдї•еЬ®OpenAIжЙУйА†зЪДдљУй™МзљСзЂЩдЄ≠зЫіжО•еЕНиієдљњзФ®гАВ

дїОеХЖдЄЪиІТеЇ¶зЬЛпЉМињЩдЄ™еЖ≥з≠ЦжЧ©жЩЪи¶БеБЪеЗЇгАВдЄНзЃ°жАОдєИиѓіпЉМжЬЙдЇЫдЉБдЄЪеЃҐжИЈж∞ЄињЬдЄНеПѓиГљжККиЗ≥еЕ≥йЗНи¶БзЪДжХ∞жНЃдЄКдЉ†еИ∞зђђдЄЙжЦєеє≥еП∞пЉМжФњеЇЬйГ®йЧ®е∞±жЫіжШѓе¶Вж≠§гАВдЄОеЕґжККињЩзЙЗеєњйШФзЪДеЄВеЬЇзХЩзїЩзЂЮдЇЙеѓєжЙЛеН†йҐЖпЉМдЄНе¶ВиЗ™еЈ±еОїеН†йҐЖгАВе¶ВжЮЬзЂЮдЇЙеѓєжЙЛжКАжЬѓињЫж≠•зЪДйАЯеЇ¶жЕҐдЄАзВєпЉМOpenAIйЗНињФеЉАжЇРиµЫйБУзЪДйАЯеЇ¶жИЦиЃЄдєЯдЉЪжЕҐдЄАзВєпЉМдљЖдєЯеП™жШѓжЕҐдЄАзВєиАМеЈ≤гАВ
еЬ®OpenAIеЉАжЇРдєЛеЙНпЉМеЫљеЖЕзЪДе§Іж®°еЮЛеЉАжЇРжЧ©еЈ≤ињЫи°МеЊЧе¶ВзБЂе¶ВиНЉгАВ
ињСеЗ†дЄ™жЬИжЭ•пЉМиЕЊиЃѓгАБжЩЇи∞±AIгАБжШЖдїСдЄЗзїігАБйШњйЗМеЈіеЈігАБжЬИдєЛжЪЧйЭҐз≠Йе§ійГ®дЉБдЄЪеѓЖйЫЖеПСеЄГжЦ∞дЄАдї£еЉАжЇРе§Іж®°еЮЛпЉМе∞ЖAIеЉАжЇРжИШеЬЇжО®иЗ≥еЙНжЙАжЬ™жЬЙзЪДзГ≠еЇ¶гАВжНЃHugging FaceдЄ≠еЫљз§ЊеМЇзїЯиЃ°пЉМдїЕ7жЬИеНХжЬИпЉМе∞±жЬЙ16еЃґжЬЇжЮДеЕ±еЉАжЇР31дЄ™ж®°еЮЛеПКеЈ•еЕЈпЉМи¶ЖзЫЦжЦЗжЬђгАБеЫЊеГПгАБ3DзФЯжИРз≠ЙеЕ®ж®°жАБеЬЇжЩѓгАВе¶ВдїКOpenAIжРЇGPT-oss-120bеТМGPT-oss-20bдЄ§жђЊеЉАжЇРж®°еЮЛеЉЇеКњеЕ•е±АпЉМйЗКжФЊеЗЇжКАжЬѓжЩЃжГ†дњ°еПЈпЉМжЧ†зЦСдЄЇеЫљеЖЕе§Іж®°еЮЛеЉАжЇРзЂЮдЇЙж†Ље±АеЄ¶жЭ•еЈ®еПШгАВ

дїОзІѓжЮБжЦєйЭҐзЬЛпЉМеЕґеЉАжЇРи°МдЄЇдЄЇеЫљеЖЕдЉБдЄЪжПРдЊЫдЇЖе≠¶дє†еАЯйЙіеЕИињЫжКАжЬѓзЪДе•СжЬЇпЉМйАЪињЗз†Фз©ґOpenAIж®°еЮЛжЮґжЮДгАБиЃ≠зїГжЦєеЉПз≠ЙпЉМеЫљеЖЕдЉБдЄЪеПѓдї•дЉШеМЦиЗ™иЇЂж®°еЮЛпЉМеЃЮзО∞жКАжЬѓеНЗзЇІгАВ
жМСжИШдєЯйЪПдєЛиАМжЭ•гАВOpenAIеЗ≠еАЯеЕґзЯ•еРНеЇ¶дЄОжКАжЬѓйҐЖеЕИ嚥豰дЉЪеРЄеЉХйГ®еИЖеЫљеЖЕеЉАеПСиАЕдЄОзФ®жИЈиµДжЇРгАВеЫљеЖЕдЉБдЄЪе¶ВдљХеЕЕеИЖеПСжМ•жЬђеЬ∞еМЦдЉШеКњжИРдЄЇдЇЯеЊЕиІ£еЖ≥зЪДиѓЊйҐШпЉМињЩеЬЇеЕ®зРГжАІзЪДе§Іж®°еЮЛеЉАжЇРзЂЮиµЫпЉМеПѓдї•иѓізО∞еЬ®жЙНеИЪеИЪеЉАеІЛгАВ
зЫЄеЕ≥йУЊжО•пЉЪдЄ≠еЫљеМЇжФѓжМБзЪДеЕґдїЦжФѓдїШжЦєеЉПеРНеНХ
